
A New Approach to MPI in Apptainer
Contributors
Dave Godlove
While Apptainer has always supported MPI-enabled applications, it can be tricky to get them working. In this blog post, we’ll detail the “wire-up“ problem that often plagues MPI in containers, traditional approaches and their shortcomings, and provide a new approach that allows you to run completely containerized MPI!
The work detailed here has been presented at a few different conferences and meetings. Indeed, one of the motivations for this blog post is to distribute these materials in copy-paste-able format so that interested parties run the examples. You can see Jonathon Anderson present this work in detail at the 2023 HPC-AI Advisory Council Meeting at Stanford. And you can see me (Dave Godlove) present an abridged version of this work in combination with some other material at the 2023 Rocky Mountain Advanced Computing Consortium at Arizona State University.
Background info
Message Passing Interface (MPI) is one of the core technologies that underlies High Performance Computing (HPC). It allows programs to scale up to HPC cluster size, utilizing all of the cores and memory in hundreds or thousands of nodes, and it is of central importance to many HPC codes.
Apptainer was originally created for HPC, so it’s no surprise that it works seamlessly with technology like batch scheduling systems, GPUs, and high performance parallel file systems.
Apptainer’s architecture is also fully compatible with MPI, but the integration with MPI has historically been… a little less seamless.
The problem with containerized MPI (wire-up)
Users traditionally launch MPI-enabled jobs by using mpiexec / mpirun. This causes a process to reach out to a pool of nodes (typically via ssh or rsh), initiate the user-defined process on all nodes, assign each process a rank, and supply the appropriate information for communication across ranks. These initialization tasks are sometimes collectively referred to as "wire-up."
If you install MPI and an MPI-enabled application inside your container, you should simply be able to call mpiexec from within your container and have it perform wire-up across nodes, right?
Unfortunately, things are not that simple. In order for MPI to start processes on new nodes, the MPI enabled application must be accessible on those nodes. If you execute mpiexec from within your container, the MPI process ssh-es to new nodes and “escapes” the container. Now that it is outside the container, it cannot access the containerized application that it is supposed to start!
The traditional solutions (hybrid and bind models)
The most obvious solution to this containerized wire-up problem is to have MPI available on the host and in the container. This way, you can call the mpiexec command from the host system and invoke an apptainer command. Something like this:
$ mpirun -n $PROCESSES apptainer exec mpi_container.sif mpi_program --opts args
In practice, this is generally accomplished in one of two ways. In the hybrid model, the user installs MPI along with their parallel application inside the container. In the bind model, MPI is bind-mounted into the container from the host system at runtime.
Now MPI on the host systems handles wire-up, and MPI in the container handles the actual message passing. Easy, right?
The problems with the traditional containerized MPI approaches
Not so easy. First, there are several different flavors of MPI (OpenMPI, MPICH, MVAPICH, Intel, etc.). Second, each of these flavors has many different versions. The host MPI implementation used for wire-up is not guaranteed to be compatible with the containerized MPI implementation used for message passing across flavors or versions. So you need to match the MPI flavor and version inside your container to that of the host system.
But compatibility headaches don’t end there. MPI can be compiled with many different flags that provide support for lots of different technologies. And MPI can also be linked to many different libraries during compilation. These build-time considerations can affect your containerized MPI compatibility too. So you need to know some details about the host system MPI you are trying to match.
All of this MPI matching also kills portability (which is one of the main advantages of using containers in the first place). You can’t reasonably expect an MPI container that you built for one host system to run on another host system unless both hosts have the same flavor and version of MPI and they were both built with similar flags and libraries! 🙀😵
The traditional solutions to containerized MPI in detail
The basic idea of traditional containerized MPI approaches is to have an MPI implementation inside of your container that matches an implementation installed on the target host, and then to call mpiexec or similar on the host with the apptainer command so that the wire-up process launches a new container for every rank. The first two approaches only differ in how they get the MPI implementation into the container. In the hybrid approach, you install it there, while in the bind approach, you just bind-mount it in from the host.
I developed these examples on a test cluster that I can access through CIQ's partnership with Dell. (Thanks Dell! 👋) The cluster is running Slurm v22.05.2 from OpenHPC with PMI2 support (more on that later) and I have installed OpenMPI v4.1.5 in my own space with support for pmi, ucx, and libfabric. For these demos I'll be relying heavily on work carried out by my colleague Jonathon, and I'll be using a version of Wes Kendall's mpi_hello_world.c that Jonathon modified to provide additional descriptive information.
Here's the source code if you want to use it too!
// Author: Wes Kendall
// Copyright 2011 www.mpitutorial.com
// This code is provided freely with the tutorials on mpitutorial.com. Feel
// free to modify it for your own use. Any distribution of the code must
// either provide a link to www.mpitutorial.com or keep this header intact.
//
// An intro MPI hello world program that uses MPI_Init, MPI_Comm_size,
// MPI_Comm_rank, MPI_Finalize, and MPI_Get_processor_name.
//
// Modified to include getcpu() by Jonathon Anderson for ciq.com
//
#include <mpi.h>
#include <stdio.h>
#include <unistd.h>
#include <limits.h>
#include <stdlib.h>
#include <sys/syscall.h>
#include <sys/types.h>
int main(int argc, char** argv) {
// Initialize the MPI environment. The two arguments to MPI Init are not
// currently used by MPI implementations, but are there in case future
// implementations might need the arguments.
MPI_Init(NULL, NULL);
// Get the number of processes
int world_size;
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
// Get the rank of the process
int world_rank;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
// Get the name of the processor
char processor_name[MPI_MAX_PROCESSOR_NAME];
int name_len;
MPI_Get_processor_name(processor_name, &name_len);
// Get CPU and NUMA information
unsigned int cpu, node;
syscall(SYS_getcpu, &cpu, &node, NULL);
// Get mount namespace for container identity
char mnt_ns_buff[PATH_MAX];
ssize_t mnt_ns_len = readlink("/proc/self/ns/mnt", mnt_ns_buff, sizeof(mnt_ns_buff)-1);
if (mnt_ns_len == -1) {
fprintf(stderr, "error getting mount namespace\n");
exit(-1);
}
mnt_ns_buff[mnt_ns_len] = '\0';
// Print off a hello world message
printf("Hello world! Processor %s, Rank %d of %d, CPU %d, NUMA node %d, Namespace %s\n",
processor_name, world_rank, world_size, cpu, node, mnt_ns_buff);
// Finalize the MPI environment. No more MPI calls can be made after this
MPI_Finalize();
}
The hybrid model
This is probably the most popular way to run containerized MPI. You install an MPI implementation and version that matches (preferably to the patch number) the version that is installed on the host, and you compile your application in the container at build time. Then you launch your containerized MPI processes with the host MPI. The host MPI takes care of wire-up and the containerized MPI takes care of the communication during the job. The two never realize they are different.
Here is the definition file that I used to containerize OpenMPI in a way that was suitable to work with the OpenMPI in my environment. I adapted it from the (much simpler) example in the Apptainer documentation.
Bootstrap: docker
From: rockylinux:8
%files
mpi_hello_world.c /opt
%environment
# Point to OMPI binaries, libraries, man pages
export OMPI_DIR=/opt/ompi
export PATH="$OMPI_DIR/bin:$PATH"
export LD_LIBRARY_PATH="$OMPI_DIR/lib:$LD_LIBRARY_PATH"
export MANPATH="$OMPI_DIR/share/man:$MANPATH"
# Work around a problem that UCX has with unprivileged user namespaces
# See https://github.com/apptainer/apptainer/issues/769
export UCX_POSIX_USE_PROC_LINK=n
export LD_LIBRARY_PATH=/opt/ohpc/pub/mpi/ucx-ohpc/1.11.2/lib:/opt/ohpc/pub/mpi/libfabric/1.13.0/lib:/opt/ohpc/pub/mpi/ucx-ohpc/1.11.2/lib:$LD_LIBRARY_PATH
%post
dnf -y update
dnf -y install wget git gcc gcc-c++ make file gcc-gfortran bzip2 \
dnf-plugins-core findutils librdmacm-devel
dnf config-manager --set-enabled powertools
export OMPI_DIR=/opt/ompi
export OMPI_VERSION=4.1.5
export OMPI_URL="https://download.open-mpi.org/release/open-mpi/v4.1/openmpi-$OMPI_VERSION.tar.bz2"
mkdir -p /var/tmp/ompi
mkdir -p /opt
cd /var/tmp/ompi
wget https://github.com/openhpc/ohpc/releases/download/v2.4.GA/ohpc-release-2-1.el8.x86_64.rpm
dnf install -y ./ohpc-release-2-1.el8.x86_64.rpm
dnf -y update
dnf -y install libfabric-ohpc libpsm2-devel ucx-ib-ohpc ucx-ohpc slurm-ohpc \
slurm-devel-ohpc slurm-libpmi-ohpc ucx-rdmacm-ohpc ucx-ib-ohpc
export LD_LIBRARY_PATH=/opt/ohpc/pub/mpi/ucx-ohpc/1.11.2/lib:/opt/ohpc/pub/mpi/libfabric/1.13.0/lib:/opt/ohpc/pub/mpi/ucx-ohpc/1.11.2/lib:$LD_LIBRARY_PATH
cd /var/tmp/ompi
wget -O openmpi-$OMPI_VERSION.tar.bz2 $OMPI_URL && tar -xjf openmpi-$OMPI_VERSION.tar.bz2
cd /var/tmp/ompi/openmpi-$OMPI_VERSION
./configure --prefix=$OMPI_DIR --with-pmi --with-ucx=/opt/ohpc/pub/mpi/ucx-ohpc/1.11.2 --without-verbs --with-libfabric=/opt/ohpc/pub/mpi/libfabric/1.13.0
make -j8 install
cd / && rm -rf /var/tmp/ompi
export PATH=$OMPI_DIR/bin:$PATH
export LD_LIBRARY_PATH=$OMPI_DIR/lib:$LD_LIBRARY_PATH
cd /opt && mpicc -o mpi_hello_world mpi_hello_world.c
As you can see, it was no easy task to containerize MPI in this way. The version of MPI installed on the host is compiled with support from a lot of libraries installed using OpenHPC. To get things working, I needed to install many of the same OpenHPC rpms inside the container and put those libraries on the LD_LIBRARY_PATH so they were available to OpenMPI during compilation.
After building the container I created a job submission script to test it like so:
#!/bin/bash
#SBATCH --job-name apptainer-hybrid-mpi
#SBATCH -N 2
#SBATCH --tasks-per-node=1
#SBATCH --partition=opa
#SBATCH --time=00:05:00
export FI_LOG_LEVEL=info
mpirun -n 2 apptainer exec hybrid-ompi.sif /opt/mpi_hello_world
And I submitted the job to Slurm with the following:
$ sbatch job.sh
Submitted batch job 446
Because the variable FI_LOG_LEVEL is set to info, the slurm.out file is very verbose. But here are the high points.
$ grep "Hello" slurm-446.out
Hello world! Processor c6, Rank 1 of 2, CPU 0, NUMA node 0, Namespace mnt:[4026532737]
Hello world! Processor c5, Rank 0 of 2, CPU 0, NUMA node 0, Namespace mnt:[4026532721]
$ grep "Opened" slurm-446.out
libfabric:316582:core:core:fi_fabric_():1264<info> Opened fabric: psm2
libfabric:1117678:core:core:fi_fabric_():1264<info> Opened fabric: psm2
The first few lines show the two jobs that ran on two different compute nodes (c5, and c6). They both used CPU 0 and ran in two different namespaces (showing that they were in two different containers). The second series of lines shows that libfabric utilized the psm2 interface (not to be confused with PMI2) which supports the Omni-Path fabric and that the ranks were therefore communicating via high-speed interconnect.
This way of running containerized MPI jobs works, but it is very difficult to set up and the container is not portable. Even though I had intimate knowledge of the MPI installed on the host system (since I installed it myself), it still took me a long time to create a definition file that was compatible. If we tried to run this on a system with a different MPI version, chances are high that it would break.
The bind model
The bind model takes pretty much the same approach; but, instead of building a container with the MPI implementation installed in it, you bind-mount in the appropriate libraries at runtime.
The definition file that I used to accomplish an MPI run with the bind model was much simpler. Note that in this case mpi_hello_world was first compiled on the host system and then the binary was placed into the container at build time.
Bootstrap: docker
From: rockylinux:8
%files
mpi_hello_world /opt
%environment
export LD_LIBRARY_PATH=/opt/ohpc/pub/mpi/ucx-ohpc/1.11.2/lib:/opt/ohpc/pub/mpi/libfabric/1.13.0/lib:/home/user/ompi/lib:$LD_LIBRARY_PATH
export PATH=/opt/ohpc/pub/mpi/ucx-ohpc/1.11.2/bin:/opt/ohpc/pub/mpi/libfabric/1.13.0/bin:/home/user/ompi/bin:$PATH
Although the definition file is simpler overall, you can see that it has a very complicated LD_LIBRARY_PATH and PATH declaration. These libraries do not exist in the container, but will be bind mounted in from the host at runtime. It’s easy to determine the proper values for these variables by loading modules on the host system and inspecting the new values of the appropriate variables.
Even though the definition file was comparatively simple, the actual bind-path was less so. After a fair amount of trial and error, I arrived at this dark incantation. 🧙♂️
$ export APPTAINER_BINDPATH=/opt/ohpc,/usr/lib64/libevent_core-2.1.so.6,/usr/lib64/libevent_pthreads-2.1.so.6,/usr/lib64/libpmi2.so.0,/usr/lib64/libpmi.so.0,/usr/lib64/librdmacm.so.1,/usr/lib64/slurm/libslurm_pmi.so,/usr/lib64/libefa.so.1,/usr/lib64/libibverbs.so.1,/usr/lib64/libpsm2.so.2,/usr/lib64/libnl-3.so.200,/usr/lib64/libnl-route-3.so.200,/usr/lib64/libnuma.so.1
Now… let’s pause for a moment and appreciate that this APPTAINER_BINDPATH variable declaration is nothing short of bananas. 🍌🍌🍌
In the first place, I’m bind-mounting all of /opt/hpc into the container. I did this for convenience because there are a lot of libraries in that directory that the host system MPI is compiled against. But I also cringe anytime I see a ton of binaries bind-mounted indiscriminately into a container, because it breaks portability and reproducibility and is just an invitation for things to go wrong.
Second, note that everything else I’ve bind-mounted in comes from /usr/lib64 . ⚠️ This is a warning sign that nefarious shenanigans are lurking within our container. The /usr/lib64 directory contains system libraries that are tightly coupled to the GNU C library running on the host. Bind mounting them in will break the container if the host and container OS differ non-trivially. But MPI is compiled against these libraries so it is a necessary evil. 👿
Anyway, once I created this diabolical bind-mount, I created the following submission script.
#!/bin/bash
#SBATCH --job-name apptainer-bind-mpi
#SBATCH -N 2
#SBATCH --tasks-per-node=1
#SBATCH --partition=opa
#SBATCH --time=00:05:00
export FI_LOG_LEVEL=info
export APPTAINER_BINDPATH=/opt/ohpc,/usr/lib64/libevent_core-2.1.so.6,/usr/lib64/libevent_pthreads-2.1.so.6,/usr/lib64/libpmi2.so.0,/usr/lib64/libpmi.so.0,/usr/lib64/librdmacm.so.1,/usr/lib64/slurm/libslurm_pmi.so,/usr/lib64/libefa.so.1,/usr/lib64/libibverbs.so.1,/usr/lib64/libpsm2.so.2,/usr/lib64/libnl-3.so.200,/usr/lib64/libnl-route-3.so.200,/usr/lib64/libnuma.so.1
mpiexec apptainer exec bind-ompi.sif /opt/mpi_hello_world
Results with the bind model were identical to those obtained with the hybrid model.
$ grep "Hello" slurm-448.out
Hello world! Processor c6, Rank 1 of 2, CPU 0, NUMA node 0, Namespace mnt:[4026532740]
Hello world! Processor c5, Rank 0 of 2, CPU 0, NUMA node 0, Namespace mnt:[4026532724]
$ grep "Opened" slurm-448.out
libfabric:316997:core:core:fi_fabric_():1264<info> Opened fabric: psm2
libfabric:1118046:core:core:fi_fabric_():1264<info> Opened fabric: psm2
This way of running containerized MPI also works. But after compiling an MPI-enabled binary on the host, copying it into a plain container, and then bind-mounting all of the libraries and MPI executables to actually run the binary into the container as well, I found myself beginning to wonder what was the point of the container in the bind model. 🤔😕 There really doesn't seem to be any advantage (and indeed there are many disadvantages) to this approach over just running the application on bare-metal. 🤷
A new solution: the fully containerized model (using PMI)
The basic idea behind the containerized model is to put the entire MPI framework into a container along with the MPI application and then to use a tool that implements one of the PMI standards to perform the wire-up step. In this case, we are able to use PMI2 with our version of Slurm (which we installed via OpenHPC). You can check to see what versions of PMI your installation of Slurm supports like so:
$ srun --mpi=list
MPI plugin types are...
cray_shasta
none
pmi2
Check here for more information about building Slurm with PMI support.
Instead of building a complicated definition file from scratch, we will rely on Spack in this example to do the dirty work. First, we create a spack.yaml file specifying that we wanted to install. We will start by installing the OSU micro benchmarks suite along with OpenMPI and libfabric and then we will add our mpi_hello_world program later. In the yaml, we also specify that the installation should be containerized on a Rocky Linux base with a specific version of gmake, libfabric, libgfortran, and some metadata.
Here is what that looks like.
spack:
specs:
- gmake @4.3
- osu-micro-benchmarks
- openmpi fabrics=ofi +pmi +legacylaunchers
- libfabric fabrics=sockets,tcp,udp,psm2,verbs
container:
format: singularity
images:
os: rockylinux:8
spack: v0.20.0
strip: true
os_packages:
final:
- libgfortran
labels:
app: "osu-micro-benchmarks"
mpi: "openmpi"
Much simpler than the definition file I created above. But how do you use it to build a container?
The command spack containerize will spit out a definition file based on this yaml spec. (If Spack complains that rockylinux:8 is an invalid operating system, you may need to upgrade Spack.)
Using that definition file as a base, I was able to add Jonathon's mpi_hello_world.c program (in the %files section), compile it (near the end of the %post section), and then make sure it is copied to the second stage of the container build (in the %files from build section).
Here is the final definition file:
Bootstrap: docker
From: spack/rockylinux8:v0.20.0
Stage: build
%files
mpi_hello_world.c /opt
%post
# Create the manifest file for the installation in /opt/spack-environment
mkdir /opt/spack-environment && cd /opt/spack-environment
cat << EOF > spack.yaml
spack:
specs:
- gmake @4.3
- osu-micro-benchmarks
- openmpi fabrics=ofi +pmi +legacylaunchers
- libfabric fabrics=sockets,tcp,udp,psm2,verbs
concretizer:
unify: true
config:
install_tree: /opt/software
view: /opt/view
EOF
# Install all the required software
. /opt/spack/share/spack/setup-env.sh
spack -e . concretize
spack -e . install
spack gc -y
spack env activate --sh -d . >> /opt/spack-environment/environment_modifications.sh
# Strip the binaries to reduce the size of the image
find -L /opt/view/* -type f -exec readlink -f '{}' \; | \
xargs file -i | \
grep 'charset=binary' | \
grep 'x-executable\|x-archive\|x-sharedlib' | \
awk -F: '{print $1}' | xargs strip
export PATH=/opt/view/bin:$PATH
cd /opt && mpicc -o mpi_hello_world mpi_hello_world.c
Bootstrap: docker
From: docker.io/rockylinux:8
Stage: final
%files from build
/opt/spack-environment /opt
/opt/software /opt
/opt/._view /opt
/opt/view /opt
/opt/spack-environment/environment_modifications.sh /opt/spack-environment/environment_modifications.sh
/opt/mpi_hello_world /opt
%post
# Update, install and cleanup of system packages needed at run-time
dnf update -y && dnf install -y epel-release && dnf update -y
dnf install -y libgfortran
rm -rf /var/cache/dnf && dnf clean all
# Modify the environment without relying on sourcing shell specific files at startup
cat /opt/spack-environment/environment_modifications.sh >> $SINGULARITY_ENVIRONMENT
%labels
app osu-micro-benchmarks
mpi openmpi
This definition file is pretty complicated but it is very interesting for (at least) 2 reasons. First, the container actually uses Spack to do the install and because of that everything is compiled from source. Second, the definition file implements a multi-stage build where the build artifacts are copied to a clean run environment, which reduces the final container's size. 💪
Now we can use srun to launch the containerized process to take advantage of Slurm's MPI support. Here is the command:
$ FI_LOG_LEVEL=info srun --partition=opa --mpi=pmi2 --ntasks=2 --tasks-per-node=1 \
--output=slurm.out --error=slurm.out \
apptainer exec mpi-hello-world.sif /opt/mpi_hello_world
$ grep "Hello" slurm.out
Hello world! Processor c6, Rank 1 of 2, CPU 91, NUMA node 1, Namespace mnt:[4026532741]
Hello world! Processor c5, Rank 0 of 2, CPU 91, NUMA node 1, Namespace mnt:[4026532721]
$ grep "Opened" slurm.out
libfabric:80495:1686706194::core:core:fi_fabric_():1453<info> Opened fabric: psm2
libfabric:1503112:1686706194::core:core:fi_fabric_():1453<info> Opened fabric: psm2
libfabric:80495:1686706194::core:core:fi_fabric_():1453<info> Opened fabric: psm2
libfabric:1503112:1686706194::core:core:fi_fabric_():1453<info> Opened fabric: psm2
So this works without even requiring an MPI installation on the host, let alone worrying about compatibility! 🔥 🚀 🛸
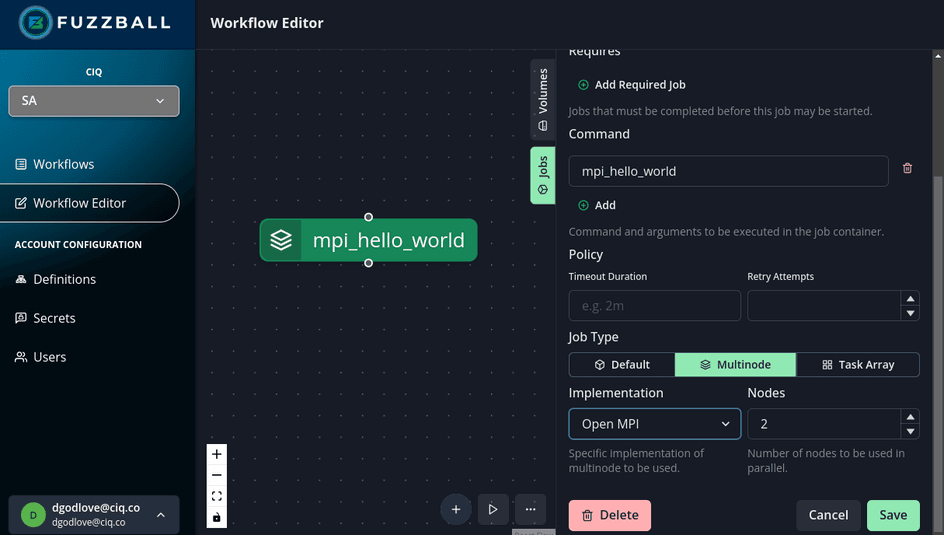
Bonus topic: Fuzzball obsoletes wire-up worries!
I’ll admit that it is kind of fun to think about the inner workings of MPI wire-up and containers and how to get them to work together as seamlessly as possible. 🤓 But… many Apptainer users have actual research to do and don’t have the bandwidth to worry about the finer points of containerized MPI. If you want your containerized MPI jobs to just work, then you should look at Fuzzball!
Fuzzball is a new container orchestration solution for jobs (as opposed to services). It includes first class support for several different types of multi-node jobs (OpenMPI, MPICH, and GASNet for programs like Chapel). It’s architecture is different from running containers under a job scheduler and it has a clean intuitive user interface. With Fuzzball, you don’t have to worry about MPI wire-up because everything runs in containers and the wire-up just works!
Contact us at CIQ to learn more about Fuzzball or anything else in this blog!



Built for scale. Chosen by the world’s best.
2.75M+
Rocky Linux instances
Being used world wide
90%
Of fortune 100 companies
Use CIQ supported technologies
250k
Avg. monthly downloads
Rocky Linux