
Workaround for Communication Issue with MPI Apps & Apptainer without Setuid
Contributors
Yoshiaki Senda
In this article, (1) we first introduce the intra-node communication issue with MPI applications and Apptainer without setuid (default version of Apptainer v1.1.x and v1.2.x) that uses unprivileged user namespace that happens with certain types of intra-node communication transport. (2) We show you test results of various MPIs, communication frameworks, interconnects, and intra-node communication transports. (3) We explain how unprivileged user namespaces with Apptainer work behind the scenes and show you the best known workaround in the mean time.
Introduction
The investigation started off by receiving an MPI runtime issue with Apptainer v1.1.x and v1.2.x (without setuid), reported by multiple users. They reported a "Permission denied" shared memory error due to the failure of opening a file descriptor under /proc/$PID/fd wIth UCX, a communication framework for high-bandwidth and low-latency networks. The typical error message is the following:
parser.c:2045 UCX INFO UCX_* env variable: UCX_LOG_LEVEL=info
ucp_context.c:2119 UCX INFO Version 1.15.0 (loaded from /opt/hpcx-v2.16/ucx/lib/libucp.so.0)
ucp_worker.c:1855 UCX INFO 0xa505d0 self cfg#0 tag(self/memory knem/memory)
ucp_worker.c:1855 UCX INFO 0xa505d0 intra-node cfg#1 tag(sysv/memory knem/memory)
ucp_context.c:2119 UCX INFO Version 1.15.0 (loaded from /opt/hpcx-v2.16/ucx/lib/libucp.so.0)
ucp_worker.c:1855 UCX INFO 0xe31f00 self cfg#0 tag(self/memory knem/memory) rma(self/memory)
ucp_worker.c:1855 UCX INFO 0xe31f00 intra-node cfg#1 tag(sysv/memory knem/memory) rma(rc_mlx5/mlx5_0:1 sysv/memory posix/memory)
mm_posix.c:233 UCX ERROR open(file_name=/proc/785917/fd/61 flags=0x0) failed: Permission denied
mm_ep.c:171 UCX ERROR mm ep failed to connect to remote FIFO id 0xc000000f400bfdfd: Shared memory error
We tested (1) OpenMPI, UCX with Omni-Path, (2) IntelMPI, libfabric with Omni-Path, and (3) HPC-X (OpenMPI, UCX) with InfiniBand against Apptainer v1.1.x and v1.2.x and observed the same error as users reported. With Apptainer v1.0.x and earlier, setuid-root mode is the default mode for those; we didn’t face this issue. We will show you test results in later sections.
Apptainer and unprivileged user namespace
Since Apptainer v1.1.0, the default mode of Apptainer is changed to “without setuid” mode that depends on the “unprivileged user namespaces” kernel feature and mount namespace. The other mode of Apptainer, such as Apptainer with setuid-root that was the default mode until v1.1.0 released, runs the container in a new mount namespace but does not run in a new user namespace. The above “Permission denied” error looks like that is derived from this change.
mpirun -np 2 apptainer run hpc.sif
|_ apptainer
| |_ process 1 (new user namespace #1/new mount namespace #1)
|_ apptainer
|_ process 2 (new user namespace #2/new mount namespace #2)
Apptainer v1.1.x and v1.2.x (default mode)
mpirun -np 2 apptainer run hpc.sif
|_ apptainer
| |_ process 1 (default user namespace #0/new mount namespace #1)
|_ apptainer
|_ process 2 (default user namespace #0/new mount namespace #2)
Apptainer v1.0.x and earlier (or apptainer-suid)
Apptainer releases the
apptainerpackage andapptainer-suidpackage for EL8/EL9 (e.g., Rocky Linux 8 and Rocky Linux 9) via EPEL and for Ubuntu Focal/Jammy via a PPA.
apptaineris the default package that uses “unprivileged user namespaces.”apptaier-suidaddssetuid-starter, an suid-root helper. With theapptainer-suidpackage, users can run containers in a new user namespace with theapptainer exec --usernscommand.
Test with various MPIs, communication frameworks, interconnects, and intra-node communication transports
In this section, we briefly explain how we replicate the issue, how we performed tests in various environments, our experiments, and our findings. We used the Intel MPI Benchmark as an example MPI application for these tests. Please see the appendix for the definition files of containers we used in this article.
Test Case 1: OpenMPI, UCX, and Omni-Path
The cluster we used here for the tests is a Warewulf v4 managed HPC cluster with a Rocky Linux 8 based image, AMD EPYC CPU, and Intel Omni-Path HFI. (Thank you, DELL!) The workload manager we used here is Slurm; OpenHPC repository was used for its installation. The Apptainer we used here is apptainer 1.2.2-1.el8 from EPEL and the host OS is Rocky Linux 8.8.
$ lspci | grep HFI
e1:00.0 Fabric controller: Intel Corporation Omni-Path HFI Silicon 100 Series [discrete] (rev 11)
The following is the job script for the first test. Thanks to Fully containerized model, we can use srun to launch MPI processes without using host side MPI.
#!/bin/bash
#SBATCH --partition=opa
#SBATCH --nodes=4
#SBATCH --ntasks-per-node=4
OMPI_MCA_pml=ucx \
OMPI_MCA_btl='^vader,tcp,openib,uct' \
UCX_LOG_LEVEL=info \
UCX_TLS=all \
UCX_NET_DEVICES=hfi1_0:1 \
SLURM_MPI_TYPE=pmi2 \
srun apptainer run ompi-imb.sif alltoall
Posix Transport Error
This is a part of the output that illustrate the errors. This posix transport error is due to the failure of opening file descriptor under /proc/$PID/fd with "Permission denied." (The UCX library inside this container is v1.10.1.)
ucp_worker.c:1720 UCX INFO ep_cfg[0]: tag(self/memory cma/memory rc_verbs/hfi1_0:1);
ucp_worker.c:1720 UCX INFO ep_cfg[1]: tag(posix/memory cma/memory rc_verbs/hfi1_0:1);
mm_posix.c:195 UCX ERROR open(file_name=/proc/158012/fd/17 flags=0x0) failed: Permission denied
mm_ep.c:155 UCX ERROR mm ep failed to connect to remote FIFO id 0xc00000044002693c: Shared memory error
The posix transport needs ptrace capability when it uses proc link (ref). The ptrace capability only works with the same or children user namespaces. As we saw in the previous section, Apptainer without setuid relies on unprivileged user namespaces, and MPI application processes spawned by MPI launcher via apptainer belongs to different user namespaces. Those processes launch a children process such as UCP Worker at MPI initialization phase. UCP Worker checks connectivity of intra-node communication transport between other UCP Workers. UCP Worker reports posix transport connectivity error at this phase, because UCP Workers are children of processes under a different user namespace.
mpirun -np 2 apptainer run hpc.sif
|_ apptainer
| |_ IMB-MPI1 (new user namespace #1/new mount namespace #1)
| |_UCX instance (UCP Worker) 1 (new user namespace #1/new mount namespace #1)
|_ apptainer
|_ IMB-MPI1 (new user namespace #1/new mount namespace #1)
|_UCX instance (UCP Worker) 2 (new user namespace #2/new mount namespace #2)
About UCP Worker, please see section 3.3 on UCX API Standard document UCX API Standard document (PDF)
Workaround for Posix Transport Error
This error can be avoid by setting a UCX_POSIX_USE_PROC_LINK=n environment variable at runtime. This switches the mode of the posix transport to not use a proc link so that it does not require ptrace capability–hence, it should work in such a case.
Verify Posix Transport Works with apptainer-suid
With UCX v1.10.1 and apptainer-suid, we also don’t see any errors. This is the sample output with apptainer-suid.
ucp_worker.c:1720 UCX INFO ep_cfg[0]: tag(self/memory cma/memory rc_verbs/hfi1_0:1);
ucp_worker.c:1720 UCX INFO ep_cfg[1]: tag(posix/memory cma/memory rc_verbs/hfi1_0:1);
ucp_worker.c:1720 UCX INFO ep_cfg[2]: tag(rc_verbs/hfi1_0:1);
UCX version difference
With the UCX master branch (before 5f00157 merged on Aug 25th) and apptainer, results are a bit different compared to UCX v1.10.0. The UCX master branch uses sysv transport for intra-node communication rather than posix transport when both transports are available. UCX v1.10.0 uses the posix transport first for intra-node communication in the same situation.
ucp_context.c:2127 UCX INFO Version 1.16.0 (loaded from /opt/ucx/lib/libucp.so.0)
parser.c:2044 UCX INFO UCX_* env variables: UCX_TLS=all UCX_LOG_LEVEL=info UCX_NET_DEVICES=hfi1_0:1
ucp_context.c:2127 UCX INFO Version 1.16.0 (loaded from /opt/ucx/lib/libucp.so.0)
ucp_worker.c:1877 UCX INFO 0x12af4a0 self cfg#0 tag(self/memory cma/memory rc_verbs/hfi1_0:1)
ucp_worker.c:1877 UCX INFO 0x12af4a0 intra-node cfg#1 tag(sysv/memory cma/memory rc_verbs/hfi1_0:1)
ucp_worker.c:1877 UCX INFO 0x12af4a0 inter-node cfg#2 tag(rc_verbs/hfi1_0:1)
ucp_worker.c:1877 UCX INFO 0x12af4a0 inter-node cfg#3 tag(rc_verbs/hfi1_0:1)
CMA transport error
When we use the sysv transport instead of the posix transport, the Intel MPI Benchmark Alltoall only runs for below 8192 bytes data transfer, and we got a cma transport error above 8192 bytes data transfer.
UCX has the threshold for using the zero-copy transfer UCX_ZCOPY_THRESH and the default value is UCX_ZCOPY_THRESH=16384 (ref). 16384 bytes transfer comes after 8192 bytes on an Alltoall test, so this explains why it failed after 8192 bytes transfer. cma is one of zero-copy transfer mechanisms.
The cma transport also needs ptrace capability, hence this transport fails with apptainer in the same situation we explained in the above section.
#----------------------------------------------------------------
# Benchmarking Alltoall
# #processes = 2
# ( 14 additional processes waiting in MPI_Barrier)
#----------------------------------------------------------------
#bytes #repetitions t_min[usec] t_max[usec] t_avg[usec]
0 1000 0.04 0.04 0.04
1 1000 0.86 0.87 0.87
2 1000 0.84 0.84 0.84
4 1000 0.84 0.84 0.84
8 1000 0.84 0.85 0.85
16 1000 0.84 0.85 0.84
32 1000 1.38 1.39 1.39
64 1000 1.37 1.38 1.38
128 1000 1.38 1.39 1.39
256 1000 1.52 1.57 1.54
512 1000 1.74 1.74 1.74
1024 1000 1.96 1.96 1.96
2048 1000 2.38 2.39 2.38
4096 1000 3.19 3.21 3.20
8192 1000 5.42 5.55 5.48
Assertion failure at /builddir/build/BUILD/opa-psm2-PSM2_11.2.230/ptl_am/ptl.c:153: nbytes == req->req_data.recv_msglen
ucp_context.c:2127 UCX INFO Version 1.16.0 (loaded from /opt/ucx/lib/libucp.so.0)
parser.c:2044 UCX INFO UCX_* env variable: UCX_LOG_LEVEL=info
ucp_context.c:2127 UCX INFO Version 1.16.0 (loaded from /opt/ucx/lib/libucp.so.0)
IMB-MPI1: Reading from remote process' memory failed. Disabling CMA support
IMB-MPI1: Reading from remote process' memory failed. Disabling CMA support
The trade-off between intra-node communication transports
UCX switches transports for intra-node communication depending on transferring data size because there is a tradeoff between single-copy transfer and zero-copy transfer. Zero-copy transfer requires a system call, and the system call introduces extra latency when transferring relatively small data. On the other hand, a single-copy transfer requires extra time for data copy. If that extra time exceeds the latency introduced by the system call, single-copy will be slower than zero-copy and vice versa.
Zero-copy actually means “single copy” and the name “zero” comes from “zero extra copies” and single-copy means “one extra copy” (ref).
There are other zero-copy type transports such as knem and xpmem. We will use knem with HPC-X later. xpmem is known for less system call usage compared to other zero-copy type transports, hence we expect good scalability compared to other zero-copy transport; but we didn’t test this transport in this article since we are focusing on the specific intra-node communication issue.
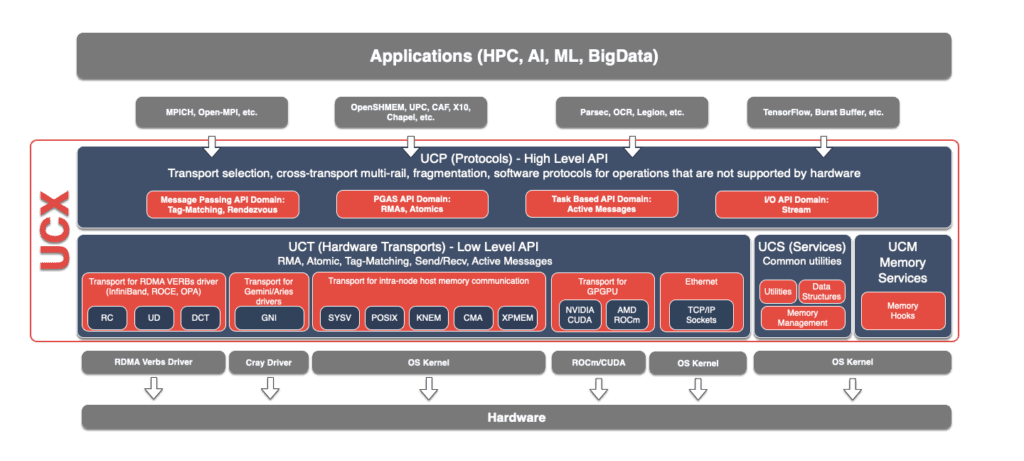
Image from: UCX architecture diagram (GitHub)
LICENSE UCX license file (GitHub)
Workaround A: manual fallback, excluding Posix and CMA for intra-node communication
We confirmed posix (proc link mode) and cma transport for intra-node communication doesn’t work between processes under different user namespaces spawned by the MPI launcher via apptainer and confirmed sysv transport works on the same case.
Excluding posix and cma transports by using UCX_TLS=^'posix,cma' may work with apptainer, so let’s test this scenario.
#!/bin/bash
#SBATCH --partition=opa
#SBATCH --nodes=4
#SBATCH --ntasks-per-node=4
OMPI_MCA_pml=ucx \
OMPI_MCA_btl='^vader,tcp,openib,uct' \
UCX_LOG_LEVEL=info \
UCX_TLS=^'posix,cma' \
UCX_NET_DEVICES=hfi1_0:1 \
SLURM_MPI_TYPE=pmi2 \
srun apptainer run ompi-imb.sif alltoall
It works and it uses sysv and ib for intra-node communication.
ucp_context.c:2127 UCX INFO Version 1.16.0 (loaded from /opt/ucx/lib/libucp.so.0)
parser.c:2044 UCX INFO UCX_* env variables: UCX_TLS=self,sysv,ib UCX_LOG_LEVEL=info UCX_NET_DEVICES=hfi1_0:1
ucp_context.c:2127 UCX INFO Version 1.16.0 (loaded from /opt/ucx/lib/libucp.so.0)
ucp_worker.c:1877 UCX INFO 0xedf1d0 self cfg#0 tag(self/memory rc_verbs/hfi1_0:1)
ucp_worker.c:1877 UCX INFO 0xedf1d0 intra-node cfg#1 tag(sysv/memory rc_verbs/hfi1_0:1)
ucp_worker.c:1877 UCX INFO 0xedf1d0 inter-node cfg#2 tag(rc_verbs/hfi1_0:1)
ucp_worker.c:1877 UCX INFO 0xedf1d0 inter-node cfg#3 tag(rc_verbs/hfi1_0:1)
This is an example output of an Alltoall result, using 16 processes (4 processes per node x 4 nodes).
The conditions and compute node specs are pretty different to other cases shown in this article. Time displayed here is not directly comparable to other cases.
#----------------------------------------------------------------
# Benchmarking Alltoall
# #processes = 16
#----------------------------------------------------------------
#bytes #repetitions t_min[usec] t_max[usec] t_avg[usec]
0 1000 0.04 0.04 0.04
1 1000 34.03 45.82 40.83
2 1000 34.20 47.19 41.27
4 1000 24.13 29.33 26.50
8 1000 24.64 29.89 26.90
16 1000 25.49 30.33 27.89
32 1000 24.13 40.25 33.37
64 1000 39.09 67.24 57.80
128 1000 45.20 61.63 55.32
256 1000 45.06 61.75 55.71
512 1000 88.64 106.03 97.98
1024 1000 50.36 103.29 65.57
2048 1000 53.70 101.88 69.13
4096 1000 64.13 79.01 70.60
8192 1000 89.85 106.78 99.54
16384 1000 153.38 174.32 164.66
32768 1000 283.60 399.88 359.97
65536 640 484.47 661.20 597.43
131072 320 890.77 1249.68 1112.92
262144 160 1818.17 2060.94 1981.74
524288 80 4034.32 5203.53 4689.51
1048576 40 8448.32 10160.09 9205.72
2097152 20 19451.08 21342.62 20755.74
4194304 10 37126.31 39543.59 38329.14
Workaround B: automatic fallback and user namespaces detection by UCX PR #9213
The pull request #9213 by Thomas Vegas on the UCX repository addresses this intra-node communication issue and proposed detection of user namespace difference between UCX instances and automatic fallback to sysv transport for both posix and cma.
I tested this fallback feature with UCX v1.10.1. I accessed this PR on 2023 July 17th and used the patch at that time.
On 2023 Aug 25th, UCX pull request #9213 merged to
masterbranch.
This is the sample output and this indicates sysv and ib is selected for intra-node communication.
ucp_worker.c:1720 UCX INFO ep_cfg[0]: tag(posix/memory cma/memory rc_verbs/hfi1_0:1);
ucp_worker.c:1720 UCX INFO ep_cfg[1]: tag(sysv/memory rc_verbs/hfi1_0:1);
ucp_worker.c:1720 UCX INFO ep_cfg[2]: tag(rc_verbs/hfi1_0:1);
It successfully runs and this is the sample output of Alltoall for 16 processes (4 processes per node x 4 nodes).
The conditions and compute nodes specs are pretty different to other cases shown in this article. Time displayed here is not directly comparable to other cases.
#----------------------------------------------------------------
# Benchmarking Alltoall
# #processes = 16
#----------------------------------------------------------------
#bytes #repetitions t_min[usec] t_max[usec] t_avg[usec]
0 1000 0.04 0.04 0.04
1 1000 34.72 47.37 41.16
2 1000 35.29 46.93 41.33
4 1000 24.99 28.98 26.37
8 1000 25.00 29.48 26.55
16 1000 25.22 29.96 27.06
32 1000 28.70 37.31 32.11
64 1000 44.68 66.88 57.40
128 1000 31.30 38.62 35.43
256 1000 33.18 40.86 36.88
512 1000 53.59 69.53 63.76
1024 1000 47.96 110.59 69.14
2048 1000 49.43 110.67 69.90
4096 1000 59.86 72.14 66.62
8192 1000 66.97 87.16 77.50
16384 1000 133.63 142.04 138.21
32768 1000 213.63 254.62 232.93
65536 640 423.80 489.25 441.71
131072 320 788.05 918.56 858.12
262144 160 1685.61 1876.19 1804.51
524288 80 4046.91 4349.73 4180.03
1048576 40 6056.49 7065.89 6744.36
2097152 20 13290.67 14372.73 14010.01
4194304 10 27122.13 28860.79 28179.71
Test case 2: IntelMPI, libfabric, and Omni-Path
The cluster we used here for the tests is a Warewulf v4 managed HPC cluster with a Rocky Linux 8 based image, AMD EPYC CPU, and Intel Omni-Path HFI. (Thank you, Dell!) The workload manager we used here is Slurm, and the OpenHPC repository was used for its installation. The Apptainer we used here is apptainer 1.2.2-1.el8 from EPEL and the host OS is Rocky Linux 8.8. IntelMPI is version 2021.6.0 from Intel oneAPI HPC Toolkit 2022.2.0.
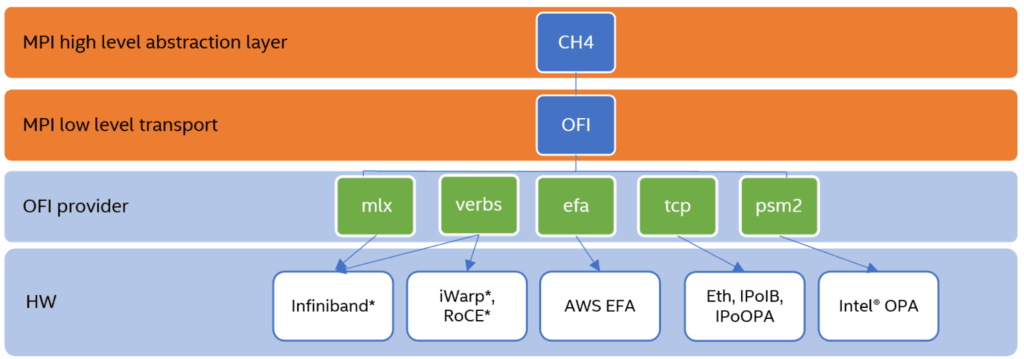
Image from: Intel MPI Library 2019 over libfabric
© Intel Corporation
The following is the job script for this environment. Thanks to the fully containerized model, we can use srun to launch MPI processes without using host side MPI. For the details of runtime switch we used here, please see Intel MPI Library Over Libfabric documentation and Libfabric Programmer's Manual.
#!/bin/bash
#SBATCH --partition=opa
#SBATCH --nodes=4
#SBATCH --ntasks-per-node=4
export I_MPI_PMI_LIBRARY=/usr/lib64/libpmi2.so.0
export I_MPI_PMI=PMI2
export I_MPI_DEBUG=4
export I_MPI_OFI_PROVIDER=psm2
export PSM2_IDENTIFY=1
export PSM2_DEVICES="shm,self,hfi1_0:1"
srun --mpi=pmi2 apptainer run mpi-imb.sif alltoall
PSM2 with libfabric 1.13.2 and PSM2 with libfabric 1.17.0
This is a sample output when we use a PSM2 OFI provider with both libfabric 1.13.2 (IntelMPI bundled version) and libfabric 1.17.0 (the Rocky Linux 8 system default version).
#----------------------------------------------------------------
# Benchmarking Alltoall
# #processes = 2
# ( 14 additional processes waiting in MPI_Barrier)
#----------------------------------------------------------------
#bytes #repetitions t_min[usec] t_max[usec] t_avg[usec]
0 1000 0.04 0.04 0.04
1 1000 1.23 1.31 1.27
2 1000 1.24 1.33 1.28
4 1000 1.23 1.34 1.29
8 1000 1.23 1.34 1.28
16 1000 1.24 1.38 1.31
32 1000 1.56 1.73 1.64
64 1000 1.51 1.66 1.59
128 1000 1.51 1.66 1.59
256 1000 1.56 1.71 1.63
512 1000 1.69 1.86 1.78
1024 1000 1.93 2.02 1.97
2048 1000 2.11 2.29 2.20
4096 1000 2.73 2.90 2.82
8192 1000 4.60 4.75 4.67
c5.150027IMB-MPI1: Reading from remote process' memory failed. Disabling CMA support
c5.150028IMB-MPI1: Reading from remote process' memory failed. Disabling CMA support
c5.150027Assertion failure at /builddir/build/BUILD/opa-psm2-PSM2_11.2.230/ptl_am/ptl.c:153: nbytes == req->req_data.recv_msglen
c5.150028Assertion failure at /builddir/build/BUILD/opa-psm2-PSM2_11.2.230/ptl_am/ptl.c:153: nbytes == req->req_data.recv_msglen
/.singularity.d/runscript: line 4: 150028 Aborted (core dumped) /opt/mpi-benchmarks/src_c/IMB-MPI1 "$@"
/.singularity.d/runscript: line 4: 150027 Aborted (core dumped) /opt/mpi-benchmarks/src_c/IMB-MPI1 "$@
Workaround A: OPX OFI provider with libfabric 1.17.0
The following is the job script for using an OPX OFI provider instead of a PSM2 OFI provider.
#!/bin/bash
#SBATCH --partition=opa
#SBATCH --nodes=4
#SBATCH --ntasks-per-node=4
export I_MPI_PMI_LIBRARY=/usr/lib64/libpmi2.so.0
export I_MPI_PMI=PMI2
export I_MPI_DEBUG=4
export I_MPI_OFI_PROVIDER=opx
export FI_LOG_LEVEL=Debug
srun --mpi=pmi2 apptainer run impi-slurm.sif alltoall
It runs successfully with an OPX OFI provider (ref1, ref2) with libfabric 1.17.0. (libfabric 1.13.2 doesn’t support the OPX OFI provider.)
#----------------------------------------------------------------
# Benchmarking Alltoall
# #processes = 16
#----------------------------------------------------------------
#bytes #repetitions t_min[usec] t_max[usec] t_avg[usec]
0 1000 0.03 0.05 0.04
1 1000 7.56 9.02 8.47
2 1000 7.42 8.88 8.33
4 1000 8.91 10.52 9.64
8 1000 8.89 10.32 9.55
16 1000 17.41 20.10 18.79
32 1000 17.62 20.63 19.16
64 1000 19.29 22.00 20.67
128 1000 22.14 25.63 24.01
256 1000 27.05 32.93 30.07
512 1000 9.91 12.91 11.27
1024 1000 12.63 17.31 15.15
2048 1000 19.19 25.31 21.93
4096 1000 34.55 41.74 37.46
8192 1000 74.98 98.33 87.40
16384 1000 133.60 165.94 150.87
32768 1000 181.36 243.23 214.27
65536 640 318.24 467.85 413.83
131072 320 624.44 918.17 797.29
262144 160 1366.07 1849.15 1599.16
524288 80 3954.24 4015.58 3988.23
1048576 40 8239.24 8445.37 8354.97
2097152 20 16091.88 16453.54 16266.20
4194304 10 27105.76 27548.96 27392.86
Test case 3: HPC-X, UCX, and NVIDIA ConnectX-6 InfiniBand
The cluster we used here for the tests is a Warewulf v4 managed HPC cluster with a Rocky Linux 9 based image, Intel Xeon Processor E5 v4 CPU, NVIDIA ConnectX-6 Infiniband, MOFED (ref), and NVIDIA HPC-X Software Toolkit (ref).
The following is the job script for this environment. Thanks to the fully containerized model, we can use srun to launch MPI processes without using host side MPI. We rebuilt OpenMPI bundled with HPC-X against the Slurm PMI library in the previous section.
#!/bin/bash
#SBATCH --partition=hpcx
#SBATCH --nodes=4
#SBATCH --ntasks-per-node=4
UCX_LOG_LEVEL=info \
srun --mpi=pmi2 apptainer run hpcx-imb.sif alltoall
Got a posix transport (proc link mode) error and an hcoll error.
ucp_context.c:2119 UCX INFO Version 1.15.0 (loaded from /opt/hpcx-v2.16-gcc-mlnx_ofed-redhat9-cuda12-gdrcopy2-nccl2.18-x86_64/ucx/lib/libucp.so.0)
parser.c:2045 UCX INFO UCX_* env variable: UCX_LOG_LEVEL=info
ucp_worker.c:1855 UCX INFO 0x1c16bd0 self cfg#0 tag(self/memory knem/memory)
ucp_worker.c:1855 UCX INFO 0x1c16bd0 intra-node cfg#1 tag(sysv/memory knem/memory)
ucp_worker.c:1855 UCX INFO 0x1c16bd0 inter-node cfg#2 tag(rc_mlx5/mlx5_0:1 rc_mlx5/mlx5_2:1)
ucp_worker.c:1855 UCX INFO 0x1c16bd0 inter-node cfg#3 tag(rc_mlx5/mlx5_0:1 rc_mlx5/mlx5_2:1)
ucp_worker.c:1855 UCX INFO 0x254c710 self cfg#0 tag(self/memory knem/memory) rma(self/memory)
ucp_worker.c:1855 UCX INFO 0x254c710 intra-node cfg#1 tag(sysv/memory knem/memory) rma(rc_mlx5/mlx5_0:1 sysv/memory posix/memory)
mm_posix.c:233 UCX ERROR open(file_name=/proc/71969/fd/99 flags=0x0) failed: Permission denied
mm_ep.c:171 UCX ERROR mm ep failed to connect to remote FIFO id 0xc0000018c0011921: Shared memory error
[LOG_CAT_P2P] UCX returned connect error: Shared memory error
[LOG_CAT_P2P] hmca_bcol_ucx_p2p_preconnect() failed
Error: coll_hcoll_module.c:310 - mca_coll_hcoll_comm_query() Hcol library init failed
But it runs successfully and got a result. The notable difference here is knem was used instead of cma.
#----------------------------------------------------------------
# Benchmarking Alltoall
# #processes = 16
#----------------------------------------------------------------
#bytes #repetitions t_min[usec] t_max[usec] t_avg[usec]
0 1000 0.03 0.04 0.03
1 1000 4.89 5.74 5.26
2 1000 4.89 5.76 5.23
4 1000 9.60 11.77 11.01
8 1000 10.36 12.46 11.67
16 1000 10.68 12.75 11.95
32 1000 11.21 13.31 12.44
64 1000 11.97 13.89 13.09
128 1000 12.34 14.55 13.72
256 1000 13.42 16.15 15.06
512 1000 7.65 10.39 9.25
1024 1000 8.76 12.10 10.63
2048 1000 12.14 15.89 14.42
4096 1000 19.92 23.51 21.97
8192 1000 38.49 45.05 41.75
16384 1000 70.44 94.53 76.79
32768 1000 132.40 179.49 148.36
65536 640 156.87 161.01 158.83
131072 320 286.91 292.65 289.76
262144 160 729.10 803.72 772.81
524288 80 1241.64 1296.77 1273.55
1048576 40 2399.29 2529.89 2485.62
2097152 20 4652.42 4853.07 4753.89
4194304 10 9854.13 10021.56 9944.17
KNEM transport
The difference between test case 1 and the above case is OpenMPI bundled with HPC-X is built against knem, the other option for zero-copy transfer. Thanks to knem, HPC-X will not fail due to user namespace separation unlike cma.
Explicitly use posix and cma
If we intentionally use posix and cma, it failed to run as expected.
#!/bin/bash
#SBATCH --partition=thor
#SBATCH --nodes=4
#SBATCH --ntasks-per-node=4
export UCX_LOG_LEVEL=info
export UCX_TLS=self,posix,cma,ib
srun --mpi=pmi2 apptainer run hpcx-imb.sif alltoall
ucp_context.c:2119 UCX INFO Version 1.15.0 (loaded from /opt/hpcx-v2.16-gcc-mlnx_ofed-redhat9-cuda12-gdrcopy2-nccl2.18-x86_64/ucx/lib/libucp.so.0)
ucp_worker.c:1855 UCX INFO 0x24ef030 self cfg#0 tag(self/memory cma/memory rc_mlx5/mlx5_0:1)
ucp_worker.c:1855 UCX INFO 0x24ef030 intra-node cfg#1 tag(posix/memory cma/memory rc_mlx5/mlx5_0:1)
mm_posix.c:233 UCX ERROR open(file_name=/proc/69802/fd/27 flags=0x0) failed: Permission denied
mm_ep.c:171 UCX ERROR mm ep failed to connect to remote FIFO id 0xc0000006c000ff24: Shared memory error
pml_ucx.c:424 Error: ucp_ep_create(proc=13) failed: Shared memory error
Explicitly use sysv and cma
This time with sysv and cma.
#!/bin/bash
#SBATCH --partition=thor
#SBATCH --nodes=4
#SBATCH --ntasks-per-node=4
export UCX_LOG_LEVEL=info
export UCX_TLS=self,sysv,cma,ib
srun --mpi=pmi2 apptainer run hpcx-imb.sif alltoall
We got a cma error as expected.
#----------------------------------------------------------------
# Benchmarking Alltoall
# #processes = 2
# ( 14 additional processes waiting in MPI_Barrier)
#----------------------------------------------------------------
#bytes #repetitions t_min[usec] t_max[usec] t_avg[usec]
0 1000 0.03 0.03 0.03
1 1000 0.59 0.59 0.59
2 1000 0.58 0.59 0.58
4 1000 0.58 0.59 0.58
8 1000 0.57 0.59 0.58
16 1000 0.58 0.59 0.58
32 1000 0.63 0.66 0.64
64 1000 0.63 0.65 0.64
128 1000 0.78 0.80 0.79
256 1000 0.83 0.87 0.85
512 1000 0.74 0.85 0.80
1024 1000 0.85 0.95 0.90
2048 1000 1.11 1.23 1.17
4096 1000 1.59 1.70 1.65
8192 1000 2.55 2.64 2.60
ucp_ep.c:1504 UCX DIAG ep 0x1492f8017040: error 'Connection reset by remote peer' on cma/memory will not be handled since no error callback is installed
cma_ep.c:81 process_vm_readv(pid=601257 {0x2b5a0d0,16384}-->{0x3571e30,16384}) returned -1: Operation not permitted
ucp_context.c:2119 UCX INFO Version 1.15.0 (loaded from /opt/hpcx-v2.16-gcc-mlnx_ofed-redhat9-cuda12-gdrcopy2-nccl2.18-x86_64/ucx/lib/libucp.so.0)
parser.c:2045 UCX INFO UCX_* env variables: UCX_TLS=self,sysv,cma,ib UCX_LOG_LEVEL=info
ucp_context.c:2119 UCX INFO Version 1.15.0 (loaded from /opt/hpcx-v2.16-gcc-mlnx_ofed-redhat9-cuda12-gdrcopy2-nccl2.18-x86_64/ucx/lib/libucp.so.0)
ucp_worker.c:1855 UCX INFO 0x2037070 self cfg#0 tag(self/memory cma/memory rc_mlx5/mlx5_0:1)
ucp_worker.c:1855 UCX INFO 0x2037070 intra-node cfg#1 tag(sysv/memory cma/memory rc_mlx5/mlx5_0:1)
ucp_worker.c:1855 UCX INFO 0x2037070 intra-node cfg#2 tag(sysv/memory cma/memory rc_mlx5/mlx5_0:1)
ucp_context.c:2119 UCX INFO Version 1.15.0 (loaded from /opt/hpcx-v2.16-gcc-mlnx_ofed-redhat9-cuda12-gdrcopy2-nccl2.18-x86_64/ucx/lib/libucp.so.0)
ucp_worker.c:1855 UCX INFO 0x2037070 inter-node cfg#3 tag(rc_mlx5/mlx5_0:1 rc_mlx5/mlx5_2:1)
Workaround A: explicitly use SysV and KNEM transport
HPC-X doesn’t need a workaround so far, but if you don’t want to get a runtime error message, explicitly using sysv and knem is the one way to go.
#!/bin/bash
#SBATCH --partition=thor
#SBATCH --nodes=4
#SBATCH --ntasks-per-node=4
export UCX_LOG_LEVEL=info
export UCX_TLS=self,sysv,knem,ib
srun --mpi=pmi2 apptainer run hpcx-imb.sif alltoall
It runs successfully as expected.
#----------------------------------------------------------------
# Benchmarking Alltoall
# #processes = 16
#----------------------------------------------------------------
#bytes #repetitions t_min[usec] t_max[usec] t_avg[usec]
0 1000 0.03 0.03 0.03
1 1000 4.20 5.82 5.10
2 1000 3.51 4.74 4.19
4 1000 4.05 5.35 4.63
8 1000 4.87 5.71 5.29
16 1000 4.34 5.56 4.92
32 1000 4.94 7.82 6.47
64 1000 5.69 8.41 6.72
128 1000 6.24 9.76 7.39
256 1000 7.63 9.03 8.28
512 1000 8.89 14.61 11.10
1024 1000 10.38 15.64 12.82
2048 1000 12.31 18.51 15.07
4096 1000 19.75 27.75 22.88
8192 1000 42.02 50.78 44.64
16384 1000 65.80 80.80 72.45
32768 1000 132.69 175.87 146.15
65536 640 147.89 153.71 150.48
131072 320 273.06 282.86 278.59
262144 160 770.78 802.63 787.77
524288 80 1435.77 1584.30 1539.48
1048576 40 2828.50 2931.49 2881.55
2097152 20 4228.95 5338.12 5182.40
4194304 10 8364.29 10358.30 10013.75
Workaround B: exclude posix and cma and leave a room for automatic transport selection
For zero-copy transfer, there is an another transport xpmem, so it’s better to exclude posix and cma and leave a room for automatic transport selection to make sure you use the best transport for your task. This is an improved version of workaround A.
#!/bin/bash
#SBATCH --partition=thor
#SBATCH --nodes=4
#SBATCH --ntasks-per-node=4
export UCX_LOG_LEVEL=info
export UCX_TLS=^'poisx,cma'
srun --mpi=pmi2 apptainer run hpcx-imb.sif alltoall
It runs successfully as expected.
#----------------------------------------------------------------
# Benchmarking Alltoall
# #processes = 16
#----------------------------------------------------------------
#bytes #repetitions t_min[usec] t_max[usec] t_avg[usec]
0 1000 0.03 0.04 0.03
1 1000 3.73 5.71 4.79
2 1000 3.37 5.21 4.36
4 1000 3.35 4.84 4.14
8 1000 3.58 5.55 4.62
16 1000 3.99 5.91 5.03
32 1000 4.96 7.41 6.38
64 1000 5.51 12.23 9.18
128 1000 6.38 8.96 7.61
256 1000 7.89 11.13 9.19
512 1000 7.93 15.19 12.40
1024 1000 9.41 17.23 14.25
2048 1000 13.53 17.91 15.82
4096 1000 22.22 26.42 24.31
8192 1000 40.75 49.02 44.47
16384 1000 68.31 77.20 73.00
32768 1000 134.80 191.12 163.20
65536 640 150.61 153.65 152.39
131072 320 273.53 281.53 278.26
262144 160 687.33 808.74 777.42
524288 80 1381.60 1631.20 1556.62
1048576 40 2811.75 3019.41 2947.42
2097152 20 4282.89 5225.62 5057.58
4194304 10 8219.96 10075.15 9753.87
Performance impact
We showed some intra-node transport doesn’t work with apptainer (Apptainer without setuid). In some cases, loss of those transports impacts performance. We will show you some examples of such cases here.
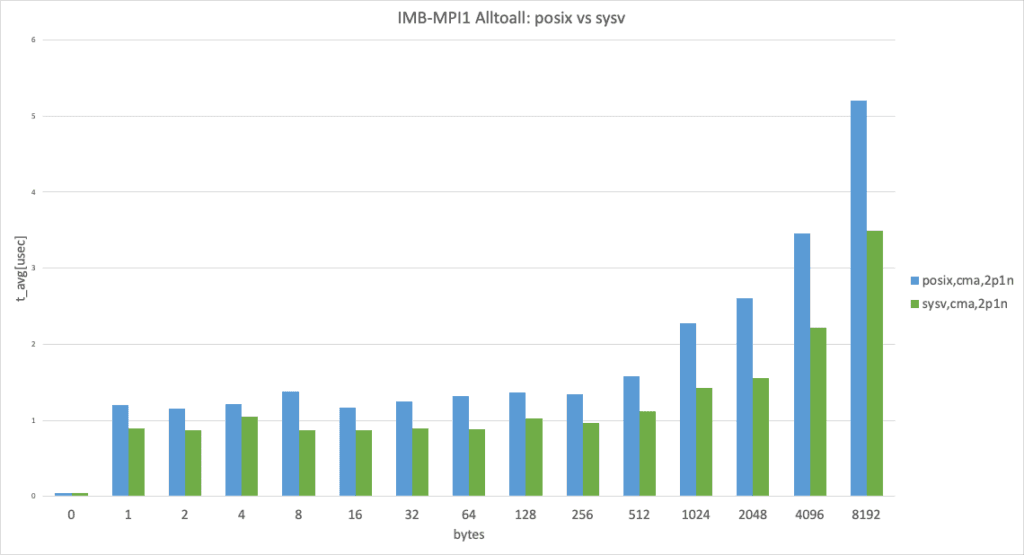
Posix transport vs. SysV transport
The graph shows Intel MPI Benchmark Alltoall results for posix, cma with apptainer-suid vs sysv, and cma with apptainer-suid to illustrate the performance difference between posix and sysv transport.
UCX has the threshold for using the zero-copy transfer UCX_ZCOPY_THRESH and the default value is UCX_ZCOPY_THRESH=16384 ; the following graphs are separated below threshold and over threshold.
2 processes per node, data size smaller than 8192 bytes
In the 2 processes per node case, sysv performed slightly better than posix. (This result takes the best result from 3 trials.)
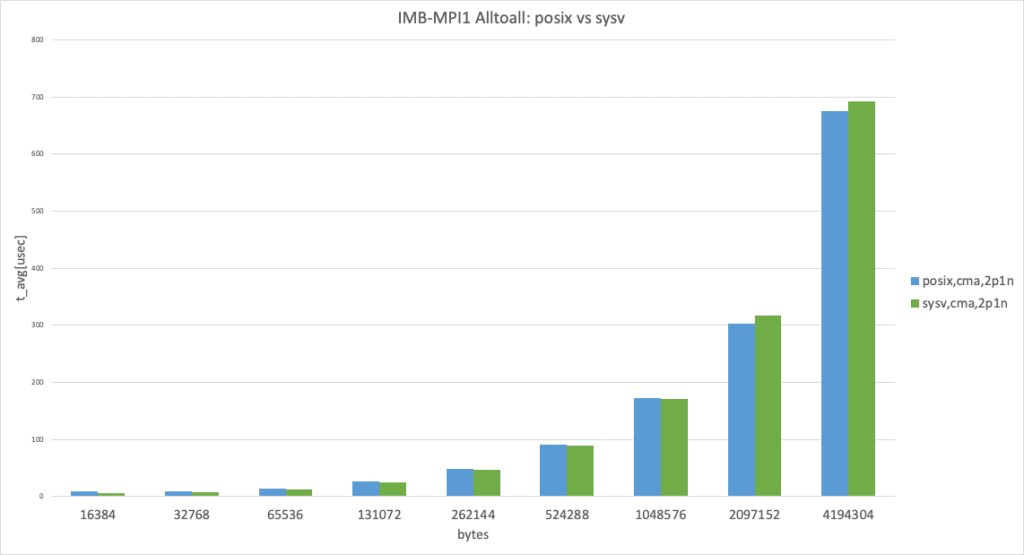
2 processes per node, data size larger than 8192 bytes
In the 2 processes per node case, cma performed almost the same, as expected. (This result takes the best result from 3 trials.)
8 processes per node, data size smaller than 8192 bytes
In the 8 processes per node case, posix and sysv performed almost the same. (This result takes the best result from 3 trials.)
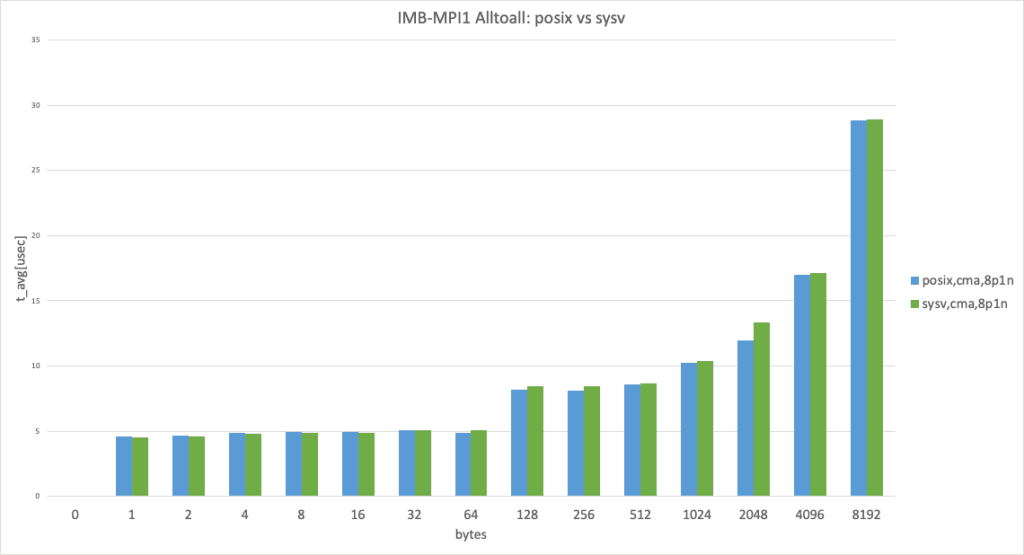
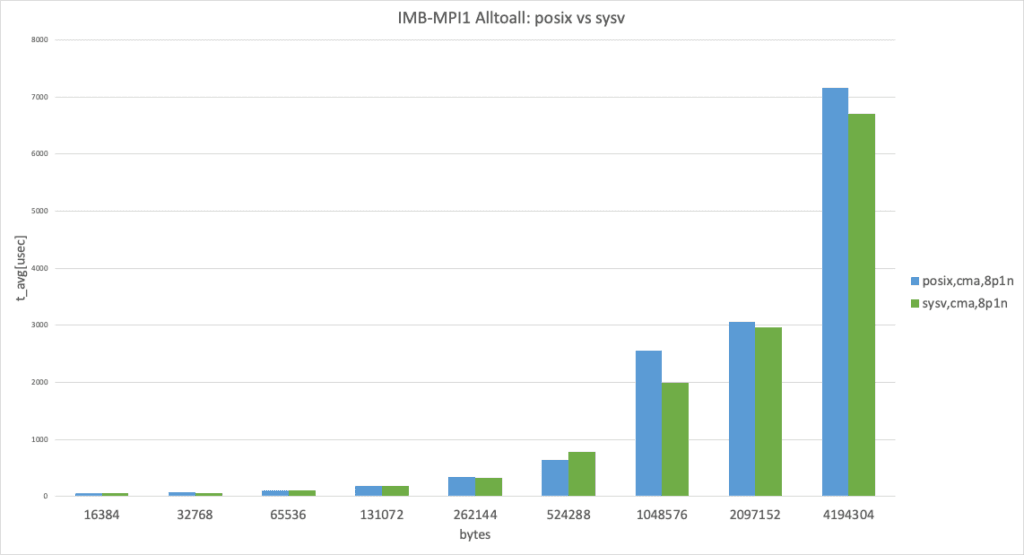
8 processes per node, data size larger than 8192 bytes
In 8 processes per node case, both use cma but unexpectedly performed slightly differently. (This result takes the best result from 3 trials.)
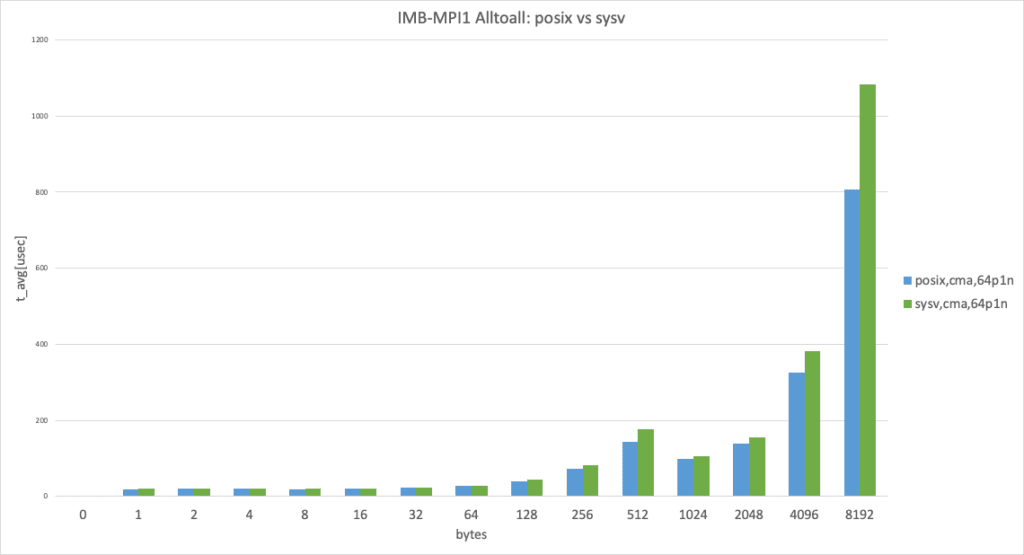
64 processes per node, data size smaller than 8192 bytes
In the 64 processes per node case, posix performed slightly better than sysv. (This result takes the best result from 3 trials.)
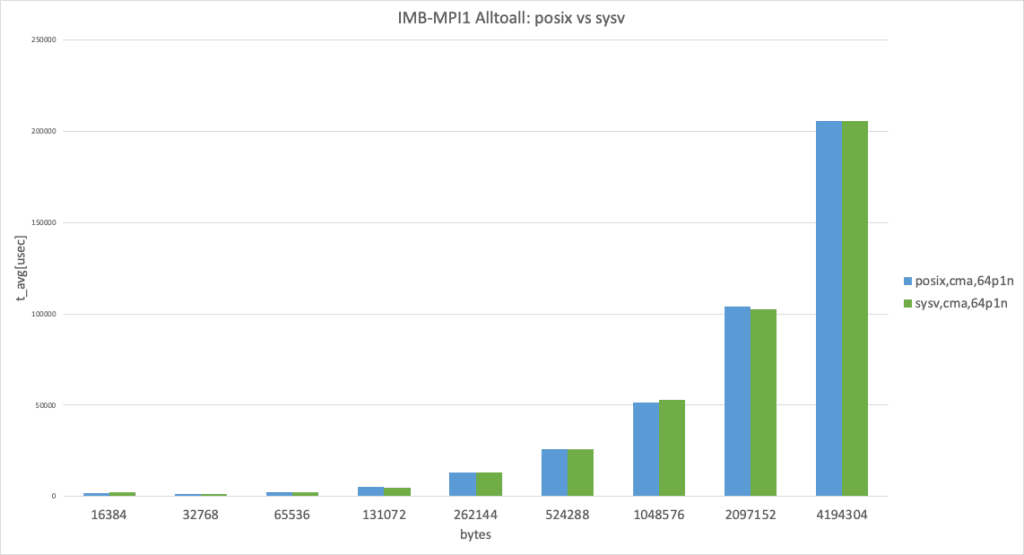
64 processes per node, data size larger than 8192 bytes
In the 64 processes per node case, cma performed almost identically, as expected. (This result takes the best result from 3 trials.)
Loss of zero-copy transfer
This graph shows Intel MPI Benchmark Alltoall results for sysv, cma with apptainer-suid vs. sysv, ib with apptainer to illustrate the performance difference between “with cma" and “without cma."
2 processes per node, data size smaller than 8192 bytes
In the 2 processes per node and data size smaller than 8192 bytes case, both used sysv and showed almost identical performance, as expected. (This result takes the best result from 3 trials.)
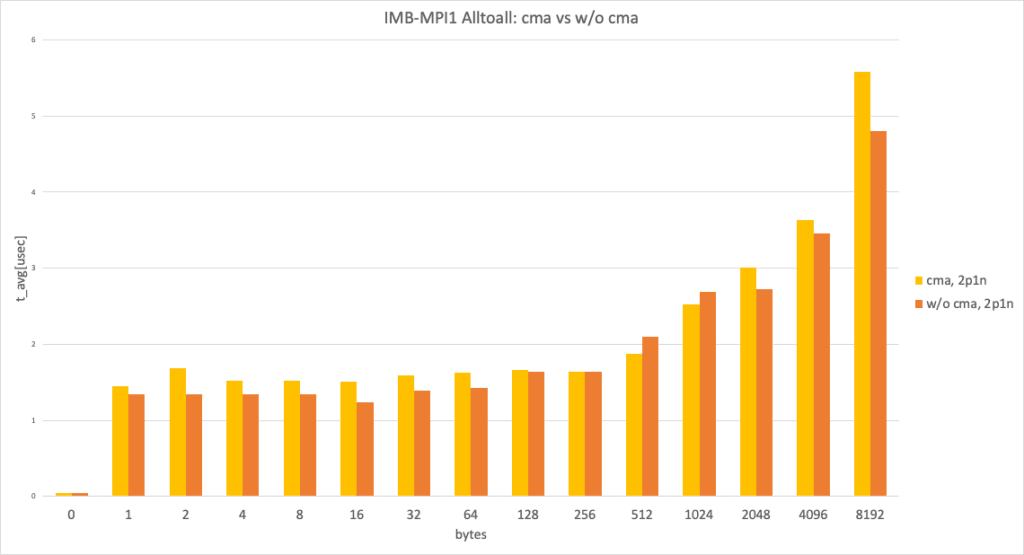
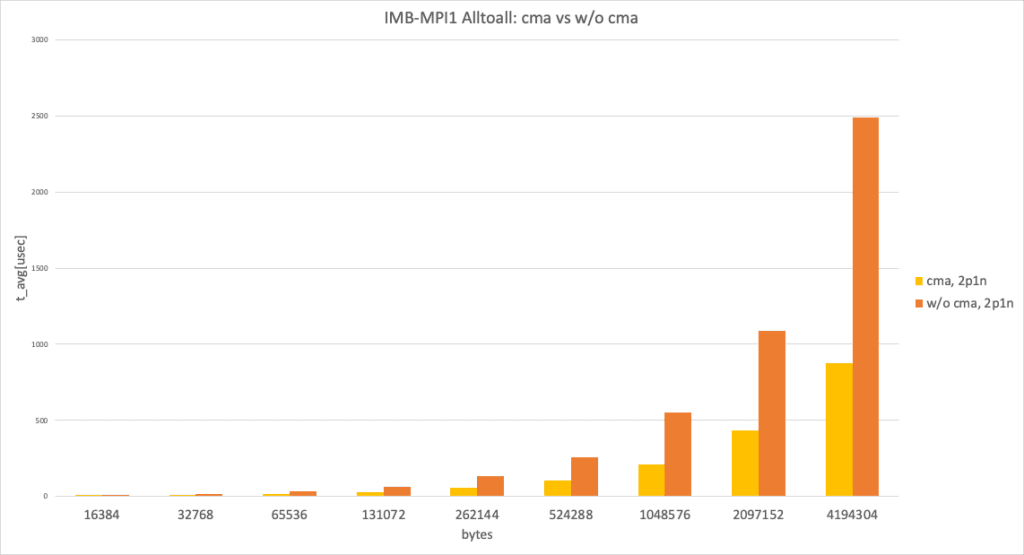
2 processes per node, data size larger than 8192 bytes
In the 2 processes per node and data size larger than 8192 bytes case, with cma and without cma showed a huge performance difference.
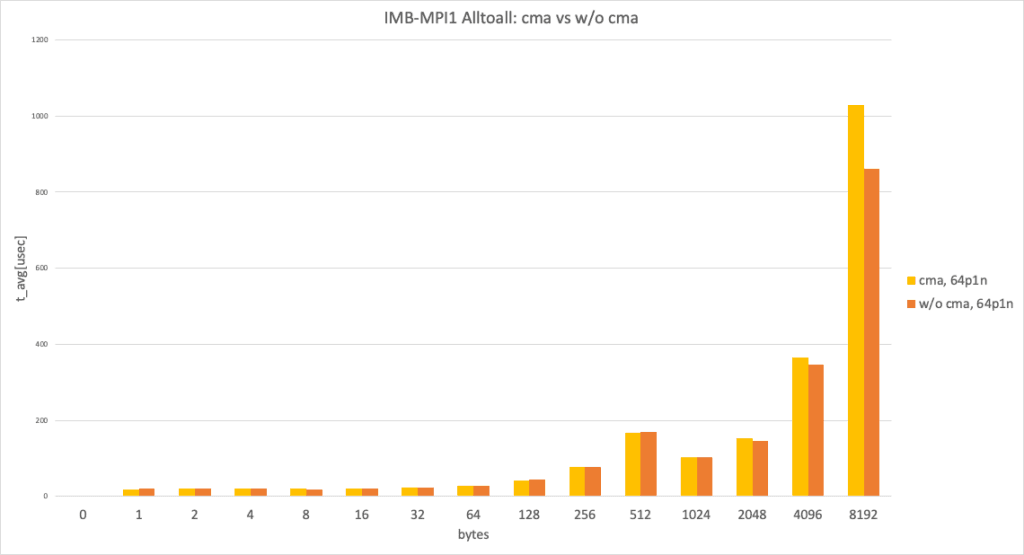
64 processes per node, data size smaller than 8192 bytes
In the 64 processes per node and data size smaller than 8192 bytes case, both used sysv and expected to show almost identical performance, but we observed a performance difference at 8192 bytes. (This result takes the best result from 3 trials.)
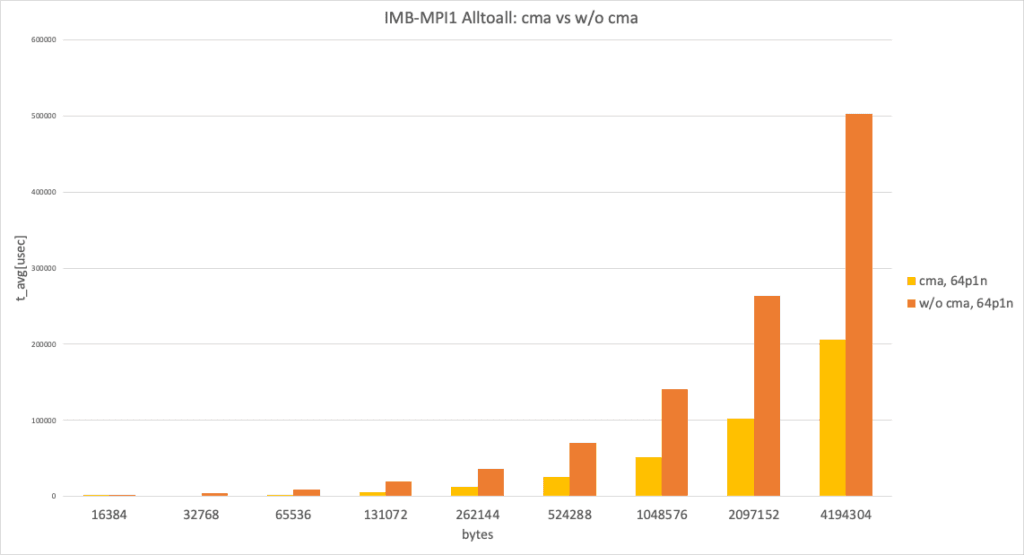
64 processes per node, data size larger than 8192 bytes
In the 64 processes per node and data size larger than 8192 bytes case, with cma and without cma showed a huge performance difference.
The case where there is no impact on performance
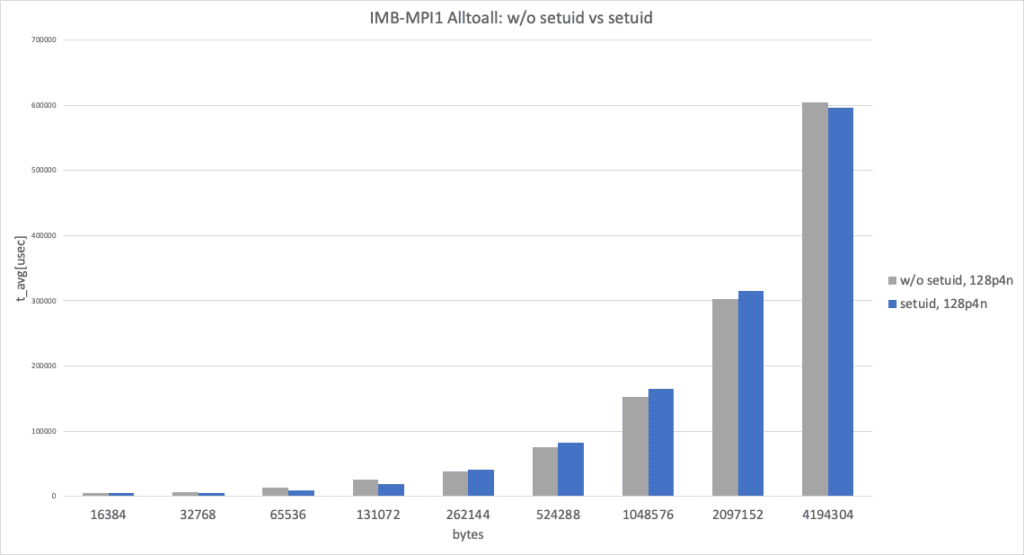
This graph shows Intel MPI Benchmark Alltoall results for sysv, knem with apptainer vs sysv, knem, hcollwith apptainer-suid to illustrate when using HPC-X there is not much difference between the two, at least for Intel MPI Benchmark on just 4 nodes, thanks to knem zero-copy transfer.
128 processes (32 processes per node x 4 nodes), data size smaller than 8192 bytes
128 processes (32 processes per node x 4 nodes) and data size smaller than 8192 bytes, without setuid and with setuid, performed almost identically.
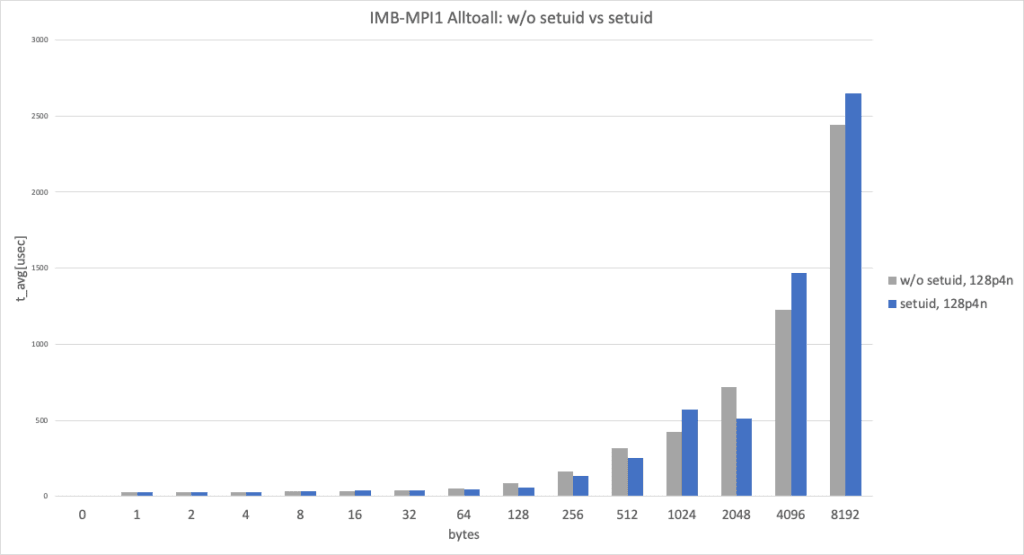
128 processes (32 processes per node x 4 nodes), data size larger than 8192 bytes
128 processes (32 processes per node x 4 nodes) and data size larger than 8192 bytes, without setuid and with setuid, performed almost identically.
Summary
If we carefully choose transports for intra-node communication case by case and for each MPI library and communication framework, MPI applications with apptainer perform the same as MPI applications with apptainer-suid do in some cases. In particular cases, we observed significant performance drop with apptainer. The best user experience for most of the HPC users would be the automatic selection of intra-node communication transports, and always performing as equivalent as apptainer-suid. Hence, a workaround for making it possible to use any intra-node communication transports while securely using MPI applications with apptainer (without setuid) is demanded.
The processes spawned by the MPI launcher with apptainer are spawned under different user namespace (see details in the next section). If the MPI launcher can spawn processes within the same user namespace, those processes can communicate using any intra-node communication transports (see details in later section).
User namespace and mount namespace of processes spawned by MPI launcher with Apptainer
The ID of user namespaces and mount namespaces can be check with file command or lsns command. Create file.def file with the following content.
Bootstrap: docker
From: rockylinux/rockylinux:9
%post
dnf install -y file
%runscript
file "$@"
and build file.sif for verifying the difference between apptainer (the default mode of v1.1.x and v1.2.x) and apptainer-suid (the default mode of v1.0.x and earlier).
Running 3 processes of file.sif using mpirun and checking mount namespace ID for each process, we can verify each process is using a different mount namespace.
$ mpirun -np 3 apptainer run file.sif /proc/self/ns/mnt
/proc/self/ns/mnt: symbolic link to mnt:[4026534271]
/proc/self/ns/mnt: symbolic link to mnt:[4026534274]
/proc/self/ns/mnt: symbolic link to mnt:[4026534276]
Running 3 processes of file.sif using mpirun and checking user namespace ID for each process, we can verify each process is using a different user namespace.
$ mpirun -np 3 apptainer run file.sif /proc/self/ns/user
/proc/self/ns/user: symbolic link to user:[4026534266]
/proc/self/ns/user: symbolic link to user:[4026534269]
/proc/self/ns/user: symbolic link to user:[4026534270]
For reference, we can check the default mount namespace ID and default user namespace ID (the namespaces that the host uses). We can verify the above 3 processes differ from the default namespace that the host uses.
$ file /proc/self/ns/mnt
/proc/self/ns/mnt: broken symbolic link to mnt:[4026531841]
$ file /proc/self/ns/user
/proc/self/ns/user: broken symbolic link to user:[4026531837]
Let’s move on to apptainer-suid , the default mode of Apptainer v1.0.x and earlier. Running 3 processes of file.sif using mpirun and checking the mount namespace ID for each process, we can verify each process is using a different mount namespace.
$ mpirun -np 3 apptainer run file.sif /proc/self/ns/mnt
/proc/self/ns/mnt: broken symbolic link to mnt:[4026532971]
/proc/self/ns/mnt: broken symbolic link to mnt:[4026532970]
/proc/self/ns/mnt: broken symbolic link to mnt:[4026532969]
Running 3 processes of file.sif using mpirun and checking user namespace ID for each process, we can verify every process is using the same user namespace as the host.
$ mpirun -np 3 apptainer run file.sif file /proc/self/ns/user
/proc/self/ns/user: broken symbolic link to user:[4026531837]
/proc/self/ns/user: broken symbolic link to user:[4026531837]
/proc/self/ns/user: broken symbolic link to user:[4026531837]
The basic idea of a workaround
A workaround for the issue is using the Apptainer instance command. The instance command was originally implemented for running services such as web servers or databases.
The instance start command allows you to create a new named instance from an existing container image that will begin running in the background. If a startscript is defined in the container metadata, the commands in that script will be executed with the instance start command as well.
We can execute a command inside an instance using apptainer exec instance://INSTANCE_NAME COMMAND and the user namespace and mount space for those processes are the same as the instance’s one. If the user namespace is the same among all the processes spawned by the MPI launcher on each node, intra-node communication transport works with apptainer (without setuid). This idea was suggested by David Dykstra from Fermilab at the Apptainer Community Meeting in response to our report.
apptainer instance start hpc.sif hpc (new user namespace #1/new mount namespace #1)
mpirun -np 2 apptainer run instance://hpc IMB-MPI1 alltoall
|_ apptainer
| |_ process 1 (user namespace #1/mount namespace #1)
|_ apptainer
|_ process 2 (user namespace #1/mount namespace #1)
Let’s verify with an example. Start the Apptainer instance by the following command.
$ apptainer instance start ys/file.sif file
INFO: instance started successfully
Spawn processes inside the instance by using MPI launcher mpirun and check the mount namespace.
$ mpirun -np 4 apptainer run instance://file /proc/self/ns/mnt
/proc/self/ns/mnt: symbolic link to mnt:[4026534270]
/proc/self/ns/mnt: symbolic link to mnt:[4026534270]
/proc/self/ns/mnt: symbolic link to mnt:[4026534270]
/proc/self/ns/mnt: symbolic link to mnt:[4026534270]
And also check the user namespace.
$ mpirun -np 4 apptainer run instance://file /proc/self/ns/user
/proc/self/ns/user: symbolic link to user:[4026534266]
/proc/self/ns/user: symbolic link to user:[4026534266]
/proc/self/ns/user: symbolic link to user:[4026534266]
/proc/self/ns/user: symbolic link to user:[4026534266]
It works as expected. Next, let’s verify this workaround works with the intra-node communication transport that didn't work before.
The Apptainer instance workaround for intra-node communication issue with MPI applications and Apptainer without setuid
The Apptainer instance workaround is the best performing workaround known in the meantime.
Single node test
This is single node test case. Start the instance, and then spawn processes inside the instance. This workaround works for both posix and cma intra-node communication transport.
apptainer instance start ys/hpcx-imb.sif hpcx
UCX_LOG_LEVEL=info \
mpirun -np 16 apptainer run instance://hpcx alltoall
Multi-node test with Slurm
This is a Slurm job script for a multi-node test case. Spawn the instance on each node and spawn processes inside the instance on each node. This workaround works for posix , cma, and hcoll.
#!/bin/bash
#SBATCH --partition=thor
#SBATCH --nodes=4
#SBATCH --ntasks-per-node=4
for node in $(srun --nodes=4 --ntasks=4 --ntasks-per-node=1 hostname)
do
ssh $node apptainer instance start ys/hpcx-imb.sif $SLURM_JOB_ID
done
UCX_LOG_LEVEL=info srun --mpi=pmi2 apptainer run instance://$SLURM_JOB_ID alltoall
srun --nodes=4 --ntasks=4 --ntasks-per-node=1 apptainer instance stop $SLURM_JOB_ID
The future plan for Apptainer v1.3.0
The above workaround works great with intra-node communication transports but it would be great if Apptainer had the option to do the above workaround or equivalent automatically in MPI context. Apptainer issue #1583 issued by Cedric Clerget is the RFE for this feature. Apptainer is planning to release this feature on the Apptainer v1.3.0 release. Stay tuned!
Appendix: How we built a container for each environment
Building an Intel MPI benchmark container for OpenMPI, UCX, and Omni-Path environment
Create an ompi-ucx-psm2-imb.def file with the following content. This definition file is following the Fully containerized model.
Bootstrap: docker
From: rockylinux/rockylinux:8
%post
dnf -y install wget git gcc gcc-c++ make file gcc-gfortran bzip2 \
dnf-plugins-core findutils librdmacm-devel epel-release unzip
crb enable
dnf -y group install "Development tools"
dnf -y install hwloc slurm-pmi slurm-pmi-devel
dnf install -y libpsm2 libpsm2-devel numactl-devel
cd /usr/src
git clone https://github.com/openucx/ucx.git ucx
cd ucx
git checkout v1.10.1
./autogen.sh
mkdir build
cd build
../configure --prefix=/opt/ucx
make -j $(nproc)
make install
cd /usr/src
git clone --recurse-submodules -b v4.1.5 https://github.com/open-mpi/ompi.git
cd ompi
./autogen.pl
mkdir build
cd build
../configure --prefix=/opt/ompi --with-ucx=/opt/ucx \
--with-slurm --with-pmi=/usr -with-hwloc=internal
make -j $(nproc)
make install
cd /opt
git clone https://github.com/intel/mpi-benchmarks.git
cd mpi-benchmarks/src_c
export PATH=/opt/ompi/bin:$PATH
make all
%runscript
/opt/mpi-benchmarks/src_c/IMB-MPI1 "$@"
Build ompi-imb.sif.
apptainer buil opmi-imb.sif ompi-ucx-psm2-imb.def
Building the Intel MPI benchmark container for IntelMPI, libfabric, and Omni-Path environment
Create an impi-libfabric-psm2-imb.def file with the following content.
Bootstrap: docker
From: rockylinux/rockylinux:8
%post
dnf -y install wget git gcc gcc-c++ make file gcc-gfortran bzip2 \
dnf-plugins-core findutils librdmacm-devel epel-release
crb enable
dnf -y group install "Development tools"
dnf -y install hwloc slurm-pmi slurm-pmi-devel
dnf install -y libpsm2 libpsm2-devel numactl-devel #For PSM2
dnf install -y libfabric #For OPX
cat << EOS > /etc/yum.repos.d/oneAPI.repo
[oneAPI]
name=Intel® oneAPI repository
baseurl=https://yum.repos.intel.com/oneapi
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://yum.repos.intel.com/intel-gpg-keys/GPG-PUB-KEY-INTEL-SW-PRODUCTS.PUB
EOS
dnf install -y intel-hpckit-2022.2.0
source /opt/intel/oneapi/setvars.sh
source /opt/intel/oneapi/mpi/2021.6.0/env/vars.sh
cd /opt
git clone https://github.com/intel/mpi-benchmarks.git
cd mpi-benchmarks/src_c
make all
%runscript
source /opt/intel/oneapi/setvars.sh
source /opt/intel/oneapi/mpi/2021.6.0/env/vars.sh
# To use system libfabric 1.17.0 instead of Intel oneAPI bundled libfabric 1.13.2
export LD_LIBRARY_PATH=/usr/lib64:$LD_LIBRARY_PATH
/opt/mpi-benchmarks/src_c/IMB-MPI1 "$@"
Build impi-imb.sif.
apptainer build impi-imb.sif impi-libfabric-psm2-imb.def
Building Intel MPI benchmark container for HPC-X, UCX, and NVIDIA ConnectX-6 InfiniBand environment
Create an hpcx-ucx-mlx5.def file with the following content. HPC-X provides a pre-built OpenMPI that works out of the box. We rebuild OpenMPI with the Slurm PMI2 library for better integration with Slurm’s srun launcher.
Bootstrap: docker
From: rockylinux/rockylinux:9
%files
hpcx-v2.16-gcc-mlnx_ofed-redhat9-cuda12-gdrcopy2-nccl2.18-x86_64.tbz /opt/hpcx-v2.16-gcc-mlnx_ofed-redhat9-cuda12-gdrcopy2-nccl2.18-x86_64.tbz
%post
dnf -y install wget git gcc gcc-c++ make file gcc-gfortran bzip2 \
dnf-plugins-core findutils librdmacm-devel epel-release
crb enable
dnf -y group install "Development tools"
dnf -y install hwloc slurm-devel
dnf -y install binutils-devel
# If you wish to install the following packages from repository hosted on mellanox.com comment out below line
# dnf config-manager --add-repo https://linux.mellanox.com/public/repo/mlnx_ofed/23.04-0.5.3.3/rhel9.2/mellanox_mlnx_ofed.repo
dnf -y install rdma-core rdma-core-devel libibverbs libibverbs-utils libibumad librdmacm librdmacm-utils
%post
dnf config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/rhel9/x86_64/cuda-rhel9.repo
dnf -y install cuda
%post
cd /opt
tar xvf hpcx-v2.16-gcc-mlnx_ofed-redhat9-cuda12-gdrcopy2-nccl2.18-x86_64.tbz
cd hpcx-v2.16-gcc-mlnx_ofed-redhat9-cuda12-gdrcopy2-nccl2.18-x86_64
HPCX_HOME=$(pwd)
source $HPCX_HOME/hpcx-init.sh
hpcx_load
cd sources
tar zxvf openmpi-gitclone.tar.gz
cd openmpi-gitclone
./configure --prefix=${HPCX_HOME}/ompi \
--with-libevent=internal \
--without-xpmem \
--with-hcoll=${HPCX_HOME}/hcoll \
--with-ucx=${HPCX_HOME}/ucx \
--with-ucc=${HPCX_HOME}/ucc \
--with-platform=contrib/platform/mellanox/optimized \
--with-slurm --with-pmi=/usr \
--with-cuda=/usr/local/cuda-12.2
make -j $(nproc)
make install
%runscript
HPCX_HOME=/opt/hpcx-v2.16-gcc-mlnx_ofed-redhat9-cuda12-gdrcopy2-nccl2.18-x86_64
source $HPCX_HOME/hpcx-init.sh
hpcx_load
"$@"
Build hpcx-ucx-mlx5.sif.
apptainer build hpcx-ucx-mlx5.sif hpcx-ucx-mlx5.def
Create an imb.def file with the following content.
Bootstrap: docker
From: rockylinux/rockylinux:9
%post
dnf -y install wget git gcc gcc-c++ make file gcc-gfortran bzip2 \
dnf-plugins-core findutils librdmacm-devel epel-release
crb enable
dnf -y group install "Development tools"
%post
git clone --recurse-submodules -b v4.1.5 https://github.com/open-mpi/ompi.git
cd ompi
./autogen.pl
mkdir build
cd build
../configure --prefix=/opt/openmpi/4.1.5
make -j $(nproc)
make install
%post
cd /opt
git clone https://github.com/intel/mpi-benchmarks.git
cd mpi-benchmarks/src_c
export PATH=/opt/openmpi/4.1.5/bin:$PATH
make all
%runscript
/opt/mpi-benchmarks/src_c/IMB-MPI1 "$@"
Build imb.sif.
apptainer build imb.sif imb.def
Create hpcx-imb.def with the following content. This is a swapping approach to prevent rebuilding Intel MPI Benchmark again and again.
Bootstrap: localimage
From: hpcx-ucx-mlx5.sif
Stage: mpi
Bootstrap: localimage
From: imb.sif
Stage: imb
Bootstrap: docker
From: rockylinux/rockylinux:9
Stage: runtime
%files from mpi
/opt/hpcx-v2.16-gcc-mlnx_ofed-redhat9-cuda12-gdrcopy2-nccl2.18-x86_64 /opt/hpcx-v2.16-gcc-mlnx_ofed-redhat9-cuda12-gdrcopy2-nccl2.18-x86_64
/usr/local/cuda-12.2 /usr/local/cuda-12.2
%files from imb
/opt/mpi-benchmarks /opt/mpi-benchmarks
%post
dnf -y install epel-release
crb enable
dnf -y install rdma-core libibverbs libibverbs-utils libibumad librdmacm librdmacm-utils
dnf -y install hwloc numactl slurm-devel
#dnf -y install nvidia-driver cuda-drivers
dnf -y clean all
%runscript
HPCX_HOME=/opt/hpcx-v2.16-gcc-mlnx_ofed-redhat9-cuda12-gdrcopy2-nccl2.18-x86_64
source $HPCX_HOME/hpcx-init.sh
hpcx_load
/opt/mpi-benchmarks/src_c/IMB-MPI1 "$@"
Build hpcx-imb.sif.
apptainer build hpcx-imb.sif hpcx-imb.def




Built for scale. Chosen by the world’s best.
2.75M+
Rocky Linux instances
Being used world wide
90%
Of fortune 100 companies
Use CIQ supported technologies
250k
Avg. monthly downloads
Rocky Linux
Have questions about your infrastructure?
Talk to a CIQ engineer about Rocky Linux, HPC, and AI infrastructure.