01
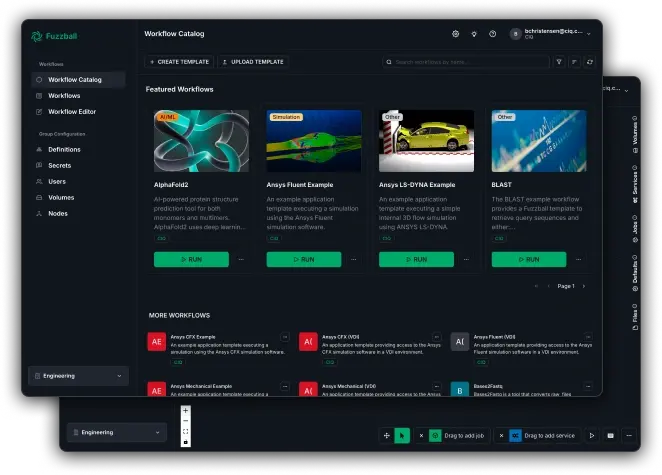
Create a new workflow
Import from a YAML file, copy a previous workflow, or start from scratch with a built-in template.
Your schedulers, storage, and workflows stay exactly as they are. Fuzzball sits above them and gives every researcher a browser-based way to submit, monitor, and reproduce jobs, so high-performance computing is no longer limited to the people who know the command line.
CIQ trusted by:
Engineers, researchers, data scientists, and AI teams move from problem to result without touching infrastructure. Administrators control every environment from one place.
CUSTOMER STORY
FYR's EV-Omics platform processes complex multi-omics data to identify precision medicine targets. With Fuzzball, their team runs reproducible analytical pipelines at production scale, cutting cycle times from days to hours.

FEDERATE
Fuzzball evaluates every available environment and places each job where it runs best, weighing cost, performance, and data locality. Develop in the cloud, run production on-premises, and burst to cloud on demand.
Fuzzball's web UI is designed for usability and standardization. Anyone can build, manage, and reuse workflows with just a few clicks:
Import from a YAML file, copy a previous workflow, or start from scratch with a built-in template.
Parameterize and customize every step of your workflow to match the needs of your jobs.
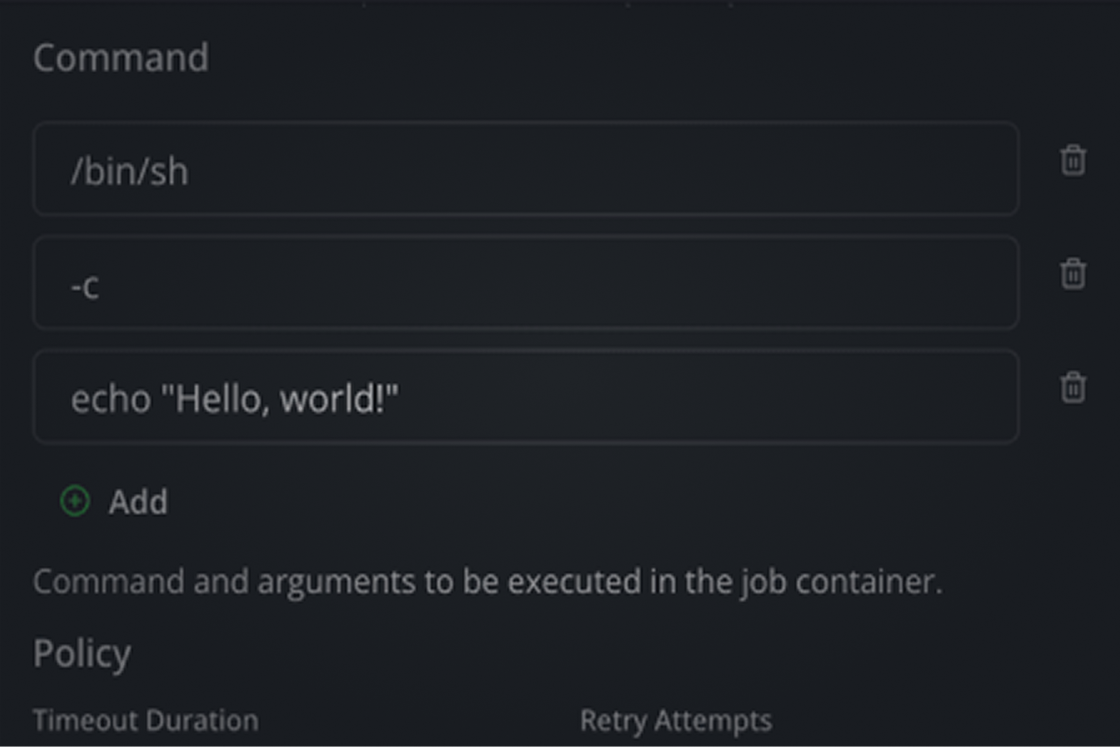
Specify infrastructure requirements, from instance sizing to storage volumes, ensuring your workflow runs efficiently.
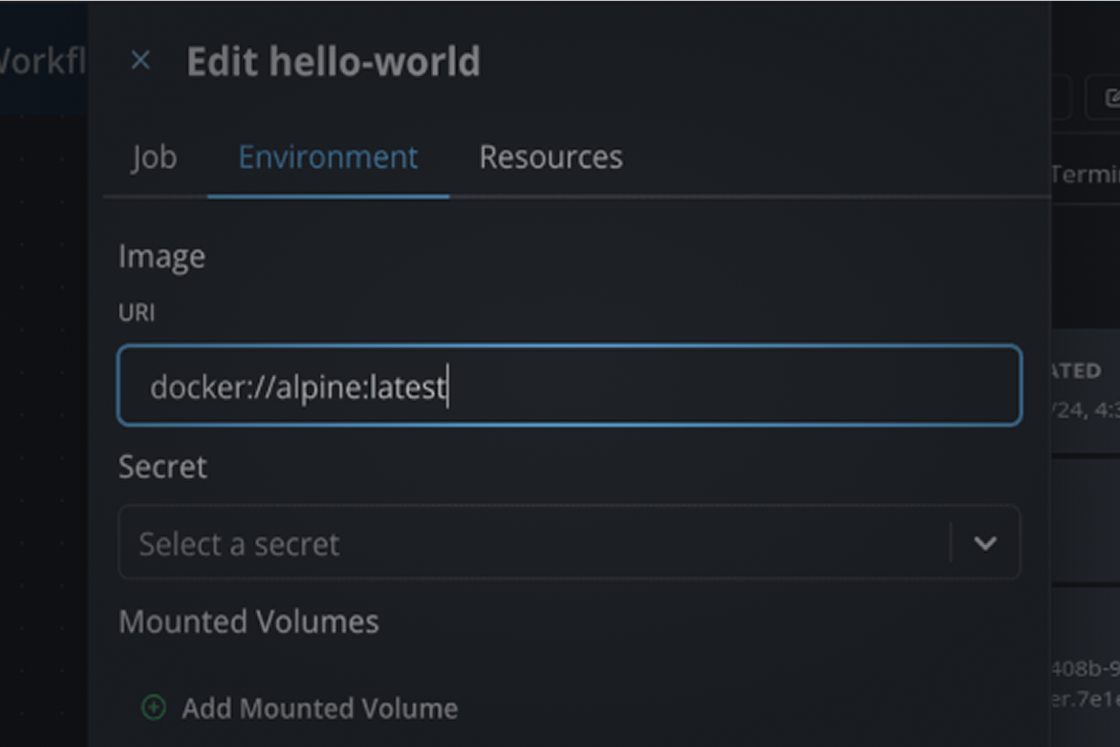
Workflows can be made into application templates, enabling applications and workflows to be used by anyone.
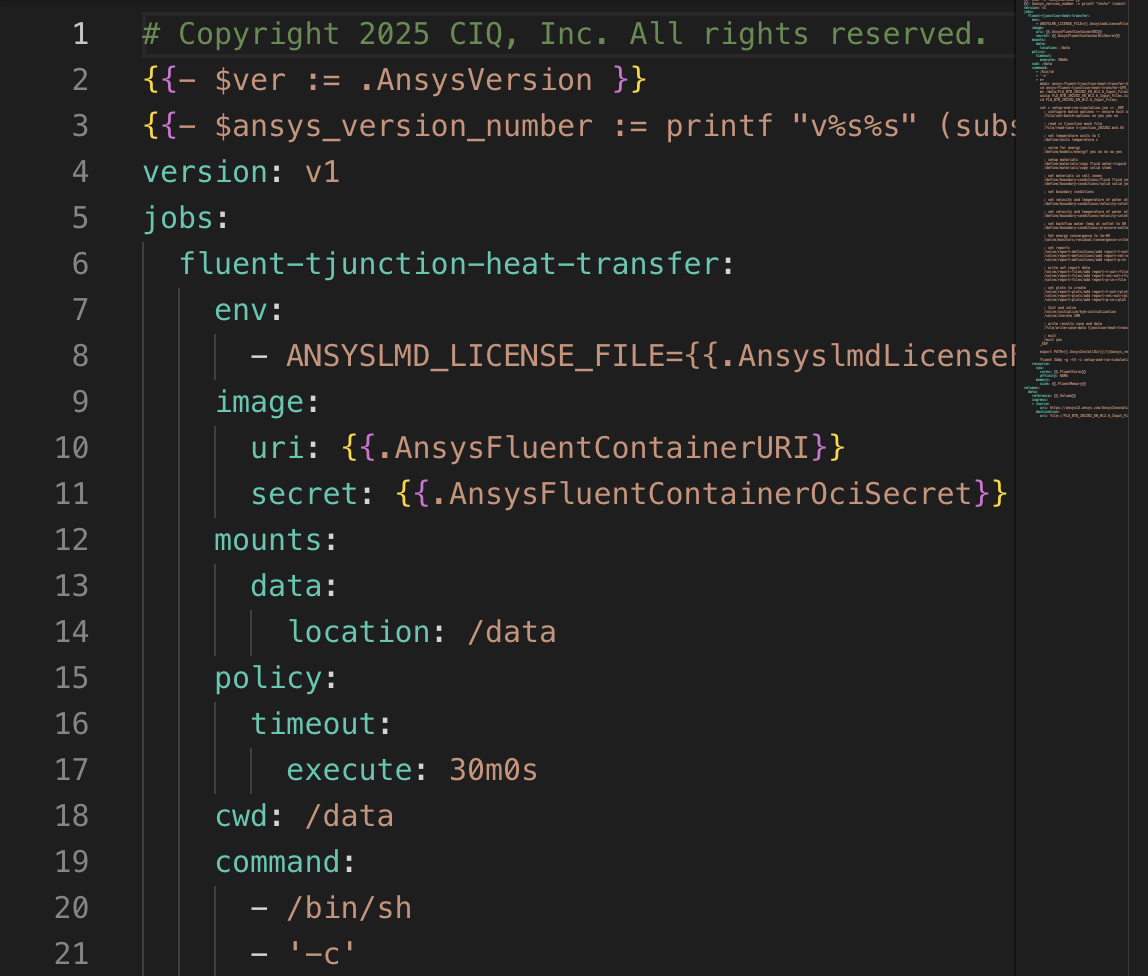
Fuzzball workflows are modular and portable. Run them on any Fuzzball cluster, chain outputs as inputs to the next workflow, and share templates across your team.
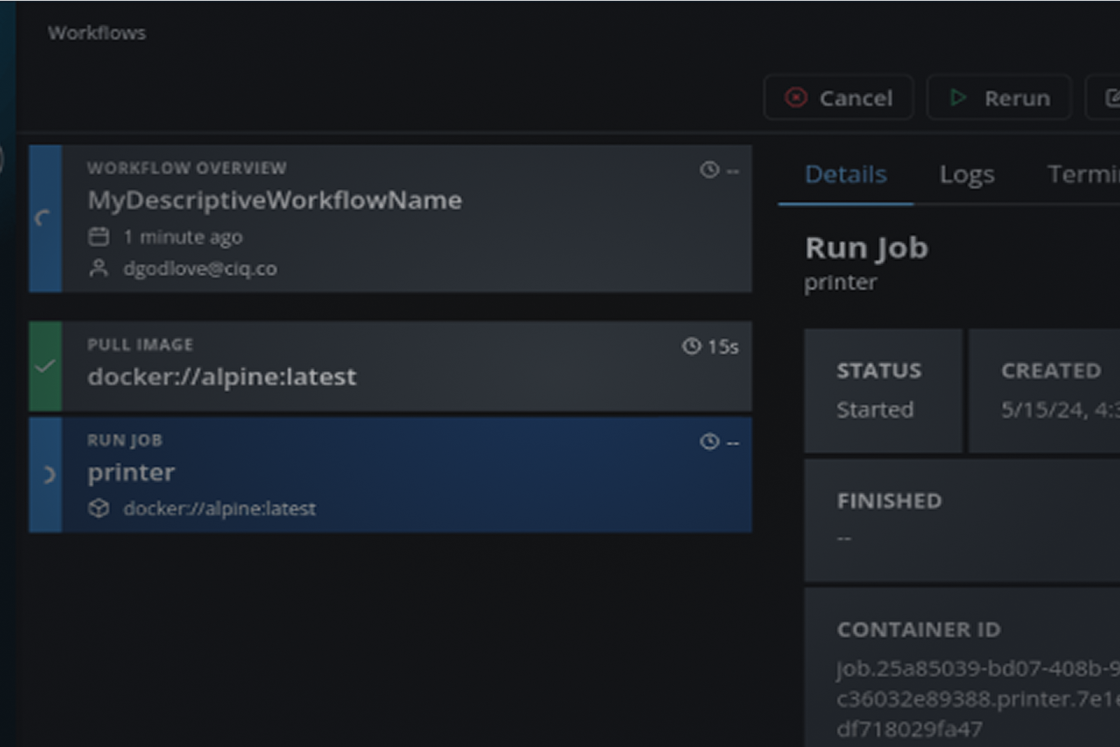
Native storage integration, a built-in object cache, and an integrated container registry are now bundled in, so there are no external services to stand up before work begins.
Deploy across AWS, Google Cloud, Oracle Cloud, CoreWeave, and Azure from one control plane.
Train a model and serve it as a live inference endpoint from a single workflow definition.
A 45-minute walkthrough of Fuzzball's core capabilities, federation architecture, and the full AI workload lifecycle.

Everything you need to evaluate Fuzzball for your environment.
Europe is building 35 AI supercomputers. The provisioning stack decides who controls them.
How to deploy your own LLM and take it to production with Fuzzball
What the world's fastest computers revealed at ISC 2026
CIQ delivers ready-to-run AI development and inference environment with latest Fuzzball capability





