
Off-the-shelf portability
Inside CIQ we have a common lament: that in traditional HPC every system is “serial number 1.” The idea is that every HPC cluster is, to a certain extent, bespoke and unique. This is definitely not true in the broad strokes: the success of the Beowulf architecture means that most HPC environments have some things in common. There is typically some kind of head node or cluster of central management services. There is typically a cluster of mostly-homogeneous compute resources connected to some kind of low-latency fabric. There’s usually some kind of central scratch storage system, and maybe some campaign or project storage, and home directories. And they usually run some kind of Linux distribution. There are commonalities for sure.
But the details matter, and in the details, no two HPC environments are quite alike. They have different versions of different software installed in different places, even at different times! Data storage paths are site-specific and possible cluster-local. And cluster access is mediated through a command-line interface that, while technically scriptable, is really only designed for human interaction or, at the very least, specific familiarity and awareness of how that specific environment is configured.
One of the primary goals of Fuzzball–the container-forward, API-first platform for hybrid performance computing–is to enable portable HPC workflows that run the same on-prem or in the cloud, today and in the future. We want Fuzzball to establish a new standard of accessibility and portability for HPC, AI, and any performance computing environment, where programmatic APIs sit alongside intuitive web interfaces and traditional command-line access. Where your workflow is data-aware, and can either automatically run where your data is or automatically stage your data to where it needs to be. And where you bring your software stack with you, giving you complete control over your job’s execution.
But resolving these portability issues positions Fuzzball to go a step beyond portability, to fully off-the-shelf HPC workflows that can run anywhere.
Why use the catalog
As I can attest from the simple experience of writing this post, it’s always more difficult to start when faced with a blank page. It’s easier to get started when you can work from an example, making iterative modifications from a known-good starting point. If you can just use the example unmodified, providing a few simple inputs, even better.
This is the promise of the Fuzzball workflow catalog.
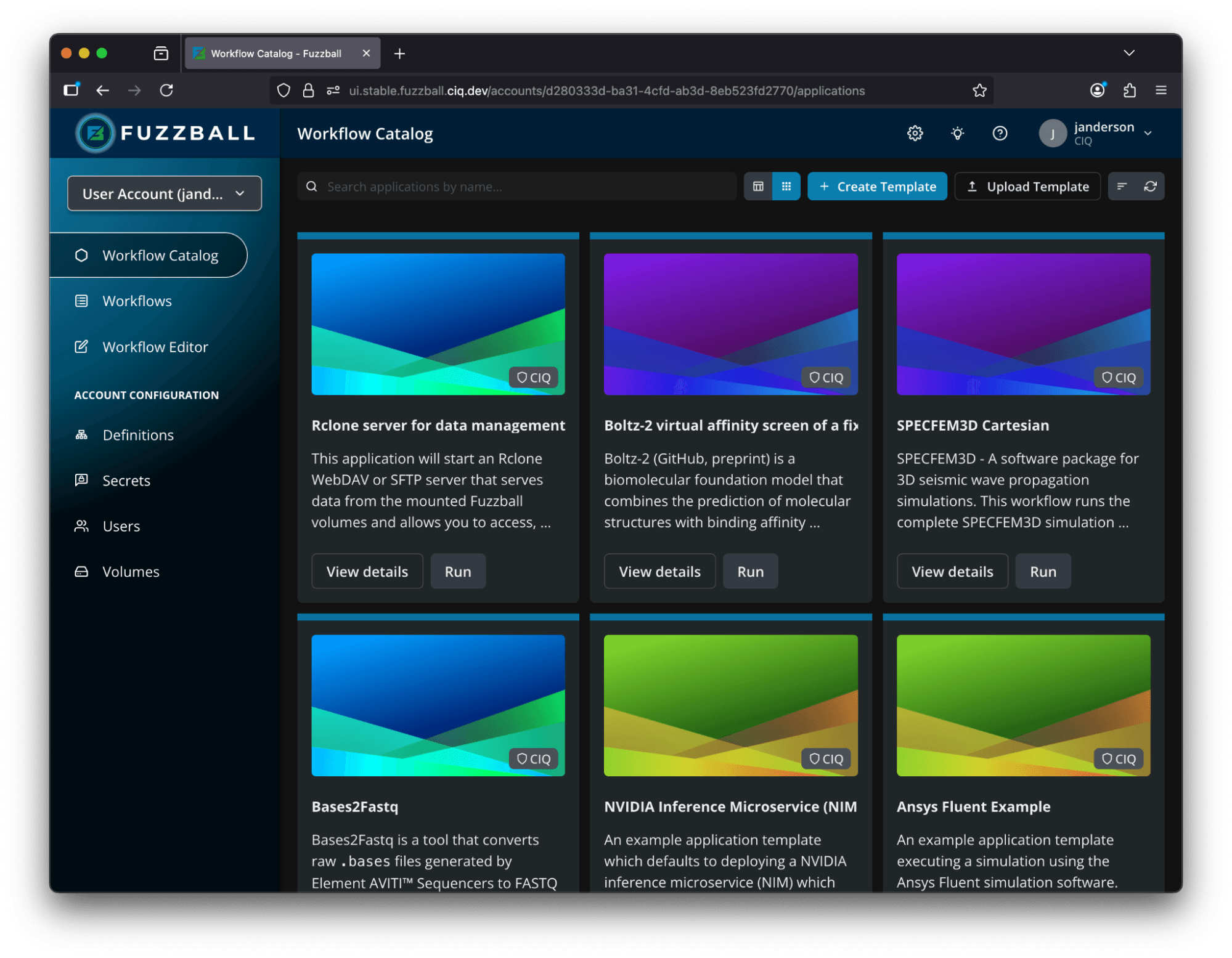
The Fuzzball workflow catalog is a collection of pre-defined workflow templates that use publicly-accessible, off-the-shelf containers to run common HPC, AI, and other workloads. Because Fuzzball jobs are always containerized, they run with their entire software stack for a repeatable, reproducible result every time. But while traditionally this has meant that you could run your workflow multiple times and get the same result, this same guarantee means that you can run someone else’s workflow and get the same result, too.
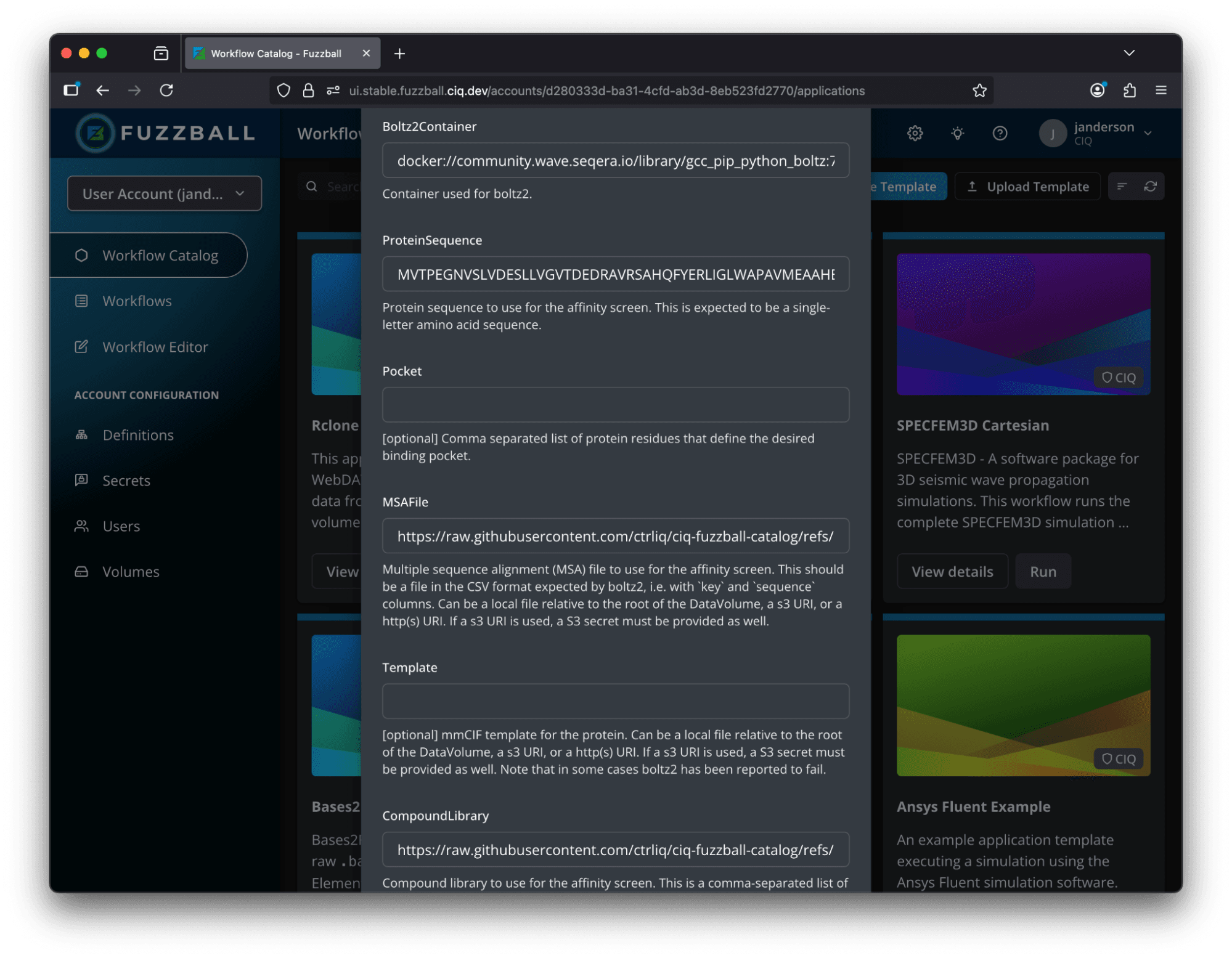
Because entries in the Fuzzball workflow catalog are templates, you don’t have to run with the same inputs, outputs, or parameters. When you run a workflow from the catalog, a simple form lets you customize the workflow for your specific run. Identify your desired input data and output storage, and Fuzzball handles data staging and volume management, whether your workflow runs on a local cluster or in a remote cloud environment.
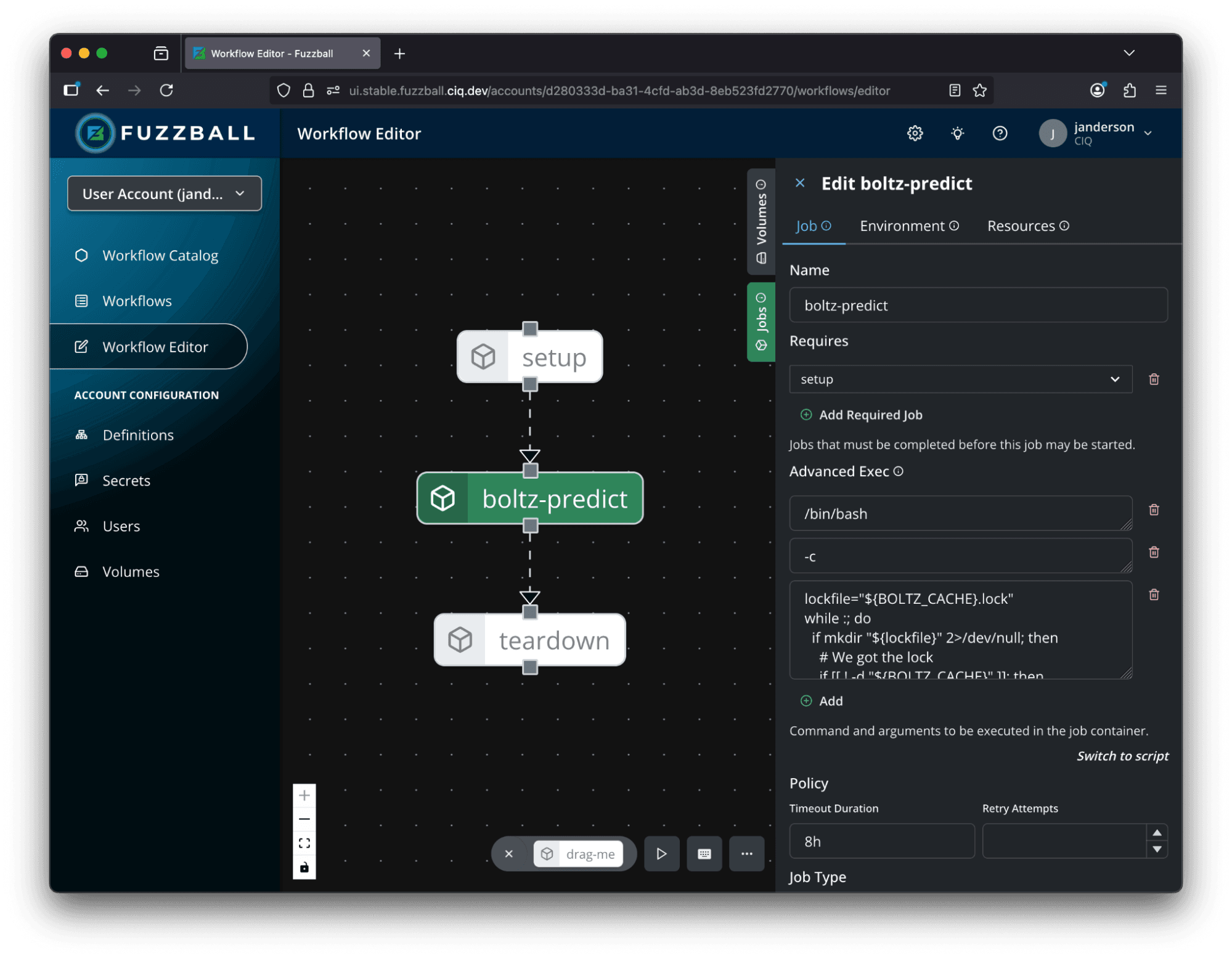
If you want to customize the workflow further, it’s just a click to open the workflow in Fuzzball’s intuitive workflow editor, where it can serve as a starting point for a more extensive custom workflow.
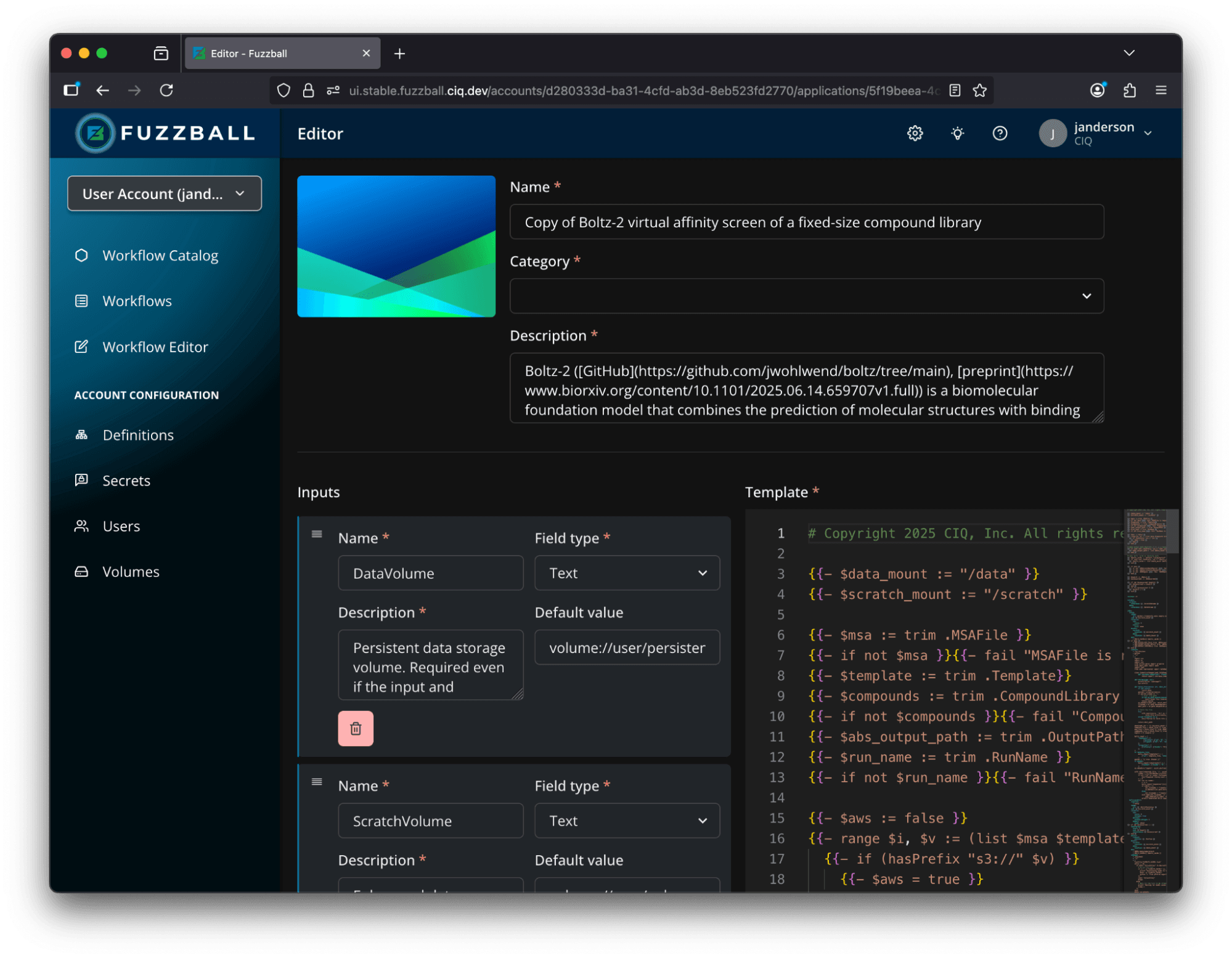
But the workflow catalog doesn’t just go in one direction: users and administrators can share their workflows in their local Fuzzball workflow catalog. This makes it easy to share work within, and even between, teams. And because Fuzzball is 100% API-driven at its core, these workflows can even serve as a foundation for automated processes, be it for model training, data analysis, or simulation.
The Fuzzball workflow catalog is a strong example of the kind of ease-of-use feature that is only possible in a system like Fuzzball, where the portability aspects of Fuzzball workflows are already taken care of. We look forward to adding additional entries to the default catalog over time, taking advantage of new Fuzzball features as they are added to the core platform, and saving everyone who uses them the time it would otherwise take to develop that same workflow from scratch in every environment they want to run in.




Built for scale. Chosen by the world’s best.
2.75M+
Rocky Linux instances
Being used world wide
90%
Of fortune 100 companies
Use CIQ supported technologies
250k
Avg. monthly downloads
Rocky Linux
Have questions about your infrastructure?
Talk to a CIQ engineer about Rocky Linux, HPC, and AI infrastructure.